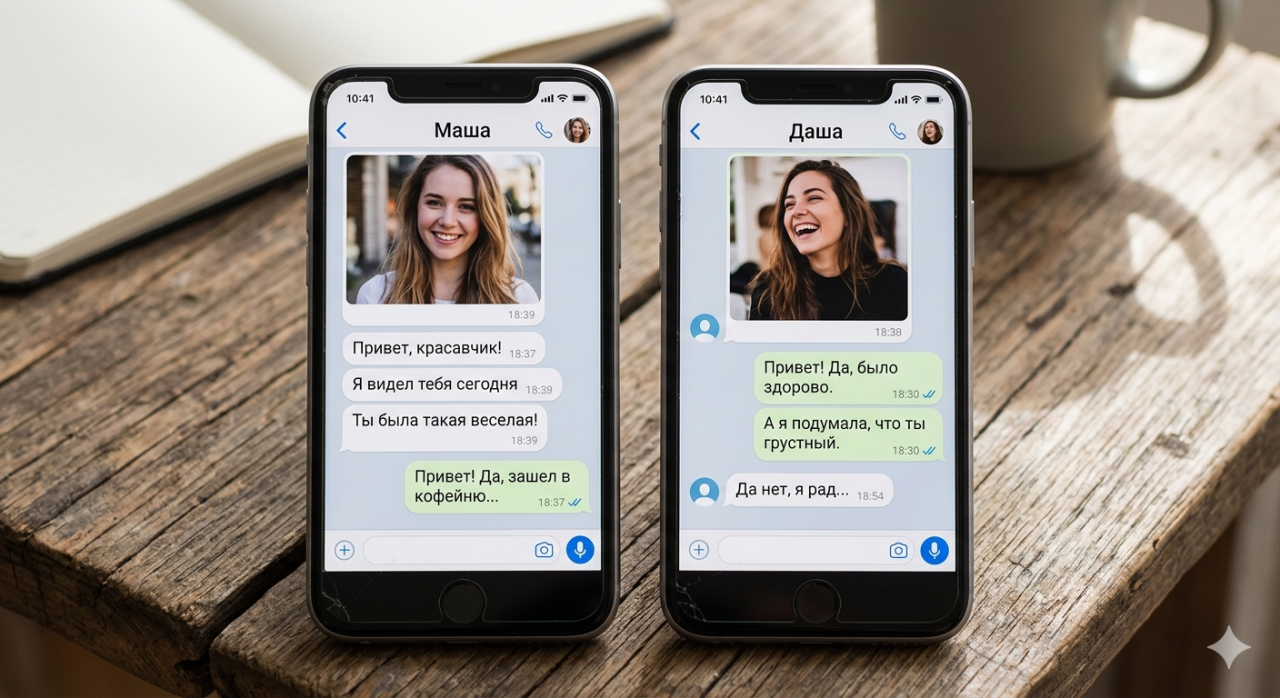
Konverzace probíhala naprosto v pořádku. Byl to neformální chat o softwarovém projektu, ten typ neformální výměny zpráv, který se mezi vývojáři mluvícími různými jazyky odehrává desítkykrát denně. Druhý člověk byl Rus, zprávy se psaly v angličtině a Google Překladač dělal tu těžkou práci s převodem všeho do ruštiny za pochodu. Asi po deseti zprávách všechno působilo hladce. Pak, zčistajasna, Rus napsal něco, co se volně přeložilo jako: „Počkej, jsi muž nebo žena?" Otázka působila bizarně. Nic v konverzaci nemělo nic společného s pohlavím. Nebyla tam žádná nejednoznačnost profilové fotky, žádný zmatek ohledně jména. Téma byla struktura databáze. A přesto z pohledu druhého člověka otázka dávala naprostý smysl.
Ruština je rodový jazyk. Slovesa v minulém čase, přídavná jména a dokonce některá podstatná jména mění tvar podle gramatického rodu mluvčího. Když někdo napíše „udělal jsem" v ruštině, koncovka slovesa řekne čtenáři, zda je mluvčí muž nebo žena. Google Překladač, pracující s nulovým kontextem o tom, kdo píše, zvolil ženské tvary sloves pro každou jedinou zprávu. Pro ruského čtenáře to vypadalo přesně tak, jako by psala žena. Skutečný mluvčí byl muž. Překladač to neměl jak vědět, protože mu to nikdo neřekl a on se nikdy nezeptal.
Nebylo to drobné stylistické zvláštnosti. Celý tón konverzace se změnil. Gramatický rod v ruštině není volitelná ozdoba. Je zakořeněn ve struktuře téměř každé věty, která odkazuje na mluvčího v minulém čase. Říct „šel jsem do obchodu" používá jiné slovo podle toho, zda šel muž nebo žena. Říct „byl jsem unavený" se mění. Říct „dokončil jsem projekt" se mění. Každé jediné vyjádření v první osobě v minulém čase vysílalo špatnou identitu po celou konverzaci a ruský účastník jednoduše předpokládal, že výstup překladače je správný.
Ten moment byl spouštěčem. Ne podráždění z jednoho špatného překladu, ale uvědomění si, že nejpoužívanější překladatelský nástroj na planetě nemá absolutně žádný mechanismus pro zjištění něčeho tak základního, jako je pohlaví mluvčího. Neptá se. Neodvozuje. Vybere výchozí hodnotu a jde dál, přičemž čtenáři ponechá vyvozovat závěry, které mohou být zcela chybné. Řešením nebyl lepší algoritmus. Řešením byl kontext.
🌐AI překladač
Překládejte, přeformulujte, opravujte a vysvětlujte texty ve 105+ jazycích. Překlad do více jazyků najednou, vlastní kontexty a akce s výběrem.
✓ 105+ jazyků✓ Překlad, přeformulování, opravy✓ Vlastní kontexty✓ Více cílů
Angličtina je jazyk, který se v běžné mluvě gramatickému rodu z velké části vyhýbá. „I went" je „I went" bez ohledu na to, kdo mluví. „I was happy" se nemění na základě identity mluvčího. To anglickým mluvčím usnadňuje zapomenout, že většina hlavních světových jazyků takto nefunguje. Ruština, arabština, hebrejština, hindština, francouzština, španělština, portugalština, němčina, polština, čeština a desítky dalších – všechny kódují rod do své gramatiky v různé míře.
Problém pro strojový překlad je přímočarý. Když je zdrojový text v angličtině, neexistují žádné rodové značky k extrakci. Věta „I was surprised" dává překladači nulovou informaci o tom, zda použít mužský nebo ženský tvar v cílovém jazyce. Lidský překladatel by se zeptal nebo by to věděl z předchozího kontextu. Strojový překladač vybere ten tvar, který se v jeho tréninkových datech objevoval častěji, což u většiny jazyků výchozí nastavení směřuje k mužskému rodu, i když ne vždy konzistentně. U Google Překladače bylo pozorováno přepínání mezi mužskými a ženskými tvary v rámci jednoho odstavce, čímž vzniká text, který vypadá, jako by mluvčí změnil pohlaví uprostřed konverzace.
Toto není okrajový případ postihující hrstku nejasných jazykových párů. Samotná ruština má přes 250 milionů mluvčích. Arabština přes 300 milionů. Španělština přes 500 milionů. Hindština přes 600 milionů. V každém z těchto jazyků špatně zvolený gramatický rod nezní jen neobratně. Vytváří skutečné zmatení ohledně toho, kdo mluví, a může podkopat důvěryhodnost celé zprávy. Obchodní návrh používající špatné rodové tvary působí v nejlepším případě nedbalé a v nejhorším automatizované. Osobní zpráva, která nesprávně identifikuje pohlaví mluvčího, je aktivně zavádějící.
Řešení implementované v YEB Translate je konceptuálně téměř trapně jednoduché, ačkoli provedení vyžadovalo pečlivý návrh. Mezi kontextovými kategoriemi dostupnými v nastavení překladu je jednou z nich pohlaví mluvčího. Jednorázové nastavení řekne AI modelu, aby používal správné rodové tvary v každém výstupu, pro každý jazyk, který to vyžaduje. Není potřeba to znovu specifikovat pro každou větu nebo odstavec. Kontext přetrvává po celou relaci a výstup čte, jako by byl napsán osobou nebo pro osobu zadaného pohlaví od úplně prvního slova.
Co kontextové kategorie skutečně dělají s překladem
Pohlaví mluvčího je jednou z deseti kontextových kategorií, které formují způsob, jakým AI vytváří své překlady. Celá sada pokrývá odvětví, cílové publikum, úroveň formálnosti, registr, tón, účel, oborovou terminologii, pohlaví mluvčího, regionální variantu a tematiku. Každá kategorie má více možností. Samotné odvětví nabízí výběr od technologií a financí po zdravotnictví, právo, marketing, vzdělávání a další. Formálnost pokrývá pět úrovní od extrémně neformální po vysoce formální. Dohromady těchto deset kategorií obsahuje 117 jednotlivých možností, které lze kombinovat pro přesný popis kontextu jakéhokoli překladového úkolu.
Navíc existuje 22 jazykových nastavení s 78 možnostmi, které řídí jazykové detaily specifické pro jednotlivé jazyky. Věci jako zda použít formální nebo neformální „vy" v jazycích, které mezi nimi rozlišují, což je téměř každý evropský jazyk kromě angličtiny. Zda preferovat latinku nebo cyrilici v srbštině. Zda použít zjednodušené nebo tradiční čínské znaky. Tato nastavení se netýkají toho, co se říká. Týkají se toho, jak se to říká, na úrovni detailu, kterou generické překladatelské nástroje jednoduše nenabízejí.
Všechna tato nastavení se sloučí do jednoho kontextového řetězce, který doprovází každý požadavek na překlad. AI model čte tento kontext předtím, než zpracuje zdrojový text, což znamená, že zná odvětví, publikum, tón, formálnost a ano, pohlaví mluvčího, než vyprodukuje jediné slovo výstupu. Výsledek není generický překlad, který je náhodou gramaticky správný. Je to překlad, který zní, jako by byl napsán někým, kdo rozumí situaci, publiku a konvencím cílového jazyka. Rozdíl mezi překladem s plným kontextem a překladem bez něj je často tak dramatický, že vypadají, jako by byly vytvořeny zcela různými nástroji. Stránka AI textový překladač prochází konkrétní příklady pro kohokoli, koho zajímá, jak moc se výstupy mohou lišit.
Konverzace, která málem zničila obchodní vztah
Když se vrátíme k původní ruské konverzaci, důsledky přesáhly chvilku trapnosti. Člověk na druhé straně strávil deset zpráv budováním mentálního obrazu toho, s kým mluví, a ten obraz byl špatný. Když přišla otázka na pohlaví a proběhla oprava, došlo v konverzaci k znatelnému resetu. Ne nepřátelství, ale překalibrace. Důvěra, která se budovala, byla lehce narušena, protože médium komunikace zaneslo falešné informace.
V neformálním chatu je to vtipná historka. V obchodním kontextu by to mohlo být opravdu škodlivé. Představte si odeslání návrhu partnerství v arabštině, kde slovesné tvary naznačují, že odesílatel je žena, když odesílatel je muž, nebo naopak. Příjemce možná nic neřekne, ale všimne si, a dojem, který zůstane, je, že odesílatel buď nerozumí jazyku, ve kterém tvrdí, že komunikuje, nebo používá nekvalitní automatizované nástroje. Ani jeden dojem nepomáhá uzavřít obchod.
Stejný princip platí pro interakce zákaznické podpory, právní komunikaci, lékařskou korespondenci a jakoukoli situaci, kde záleží na identitě mluvčího. V rodových jazycích je identita mluvčího zakódována v samotné gramatice. Odstranění této informace, nebo ještě hůř, její nesprávné doplnění, není neutrální akt. Aktivně zkresluje zprávu. Správná alternativa ke Google Překladači toto musí zvládat, a zvládnutí toho znamená dát uživateli kontrolu nad kontextem, ne se ho pokoušet odhadnout z nedostatečných dat.
Za hranice rodu: celý rozsah chybějícího kontextu
Gramatický rod je nejviditelnějším příkladem selhání kontextu v překladu, ale zdaleka ne jediným. Vezměme formálnost. V japonštině se úroveň zdvořilosti zakódovaná v řeči může lišit tak dramaticky, že stejná věta přeložená na různých úrovních formálnosti nemá téměř žádnou společnou slovní zásobu. Němčina rozlišuje mezi „du" a „Sie" pro neformální a formální oslovení. Francouzština má „tu" a „vous". Španělština má „tú" a „usted". V každém případě volba špatné úrovně formálnosti komunikuje něco o vztahu mezi mluvčím a posluchačem, a to něco může být zcela nepřesné.
Oborový žargon je další oblastí, kde je kontext nezbytný. Slovo „protokol" znamená něco konkrétního v medicíně, něco jiného v síťování a něco úplně jiného v diplomacii. „Engagement" v marketingu odkazuje na metriky interakce uživatelů. Ve vojenském kontextu odkazuje na boj. V osobním kontextu odkazuje na zásnuby. Překladač pracující bez oborového kontextu vybere ten význam, kterému dávají přednost jeho tréninková data, a pokud zdrojový text pochází z úzkého oboru, výsledek může být zcela špatný.
Návod k použití YEB Translate pokrývá celý proces nastavení, včetně konfigurace kontextových kategorií pro konkrétní pracovní postupy. Pro kohokoli, kdo zažil frustraci z překladů, které znějí neurčitě správně, ale míjejí se zamýšleným významem, je kontextový systém tím chybějícím dílem. Nedělá AI chytřejším. Dává AI informace, které potřebuje k inteligentním rozhodnutím – stejné informace, o které by lidský překladatel požádal před zahájením práce.
Často kladené otázky
Zvládá Google Překladač gramatický rod správně
Google Překladač se neptá na pohlaví mluvčího ani s ním nepočítá. Při překladu z angličtiny do rodových jazyků jako ruština, arabština nebo španělština výchozí nastavení směřuje k tomu tvaru, který se v tréninkových datech vyskytoval nejčastěji. To může vést k používání špatného rodu v celé konverzaci, což vytváří zmatek pro čtenáře a nesprávně reprezentuje identitu mluvčího.
Existuje bezplatný AI překladač s kontextovými nastaveními
YEB Translate používá model platby za použití kreditů namísto předplatného. Kredity se spotřebovávají pouze při skutečném zpracování textu a kontextový systém se všemi deseti kategoriemi je dostupný při každém požadavku. Neexistuje žádná oddělená cenová úroveň pro kontextový překlad.
Co je kontextový překlad a proč je důležitý
Kontextový překlad znamená, že AI model dostane informace o mluvčím, publiku, odvětví, úrovni formálnosti a dalších faktorech předtím, než vygeneruje překlad. Tyto informace formují volbu slov, gramatiku, tón a registr ve výstupu. Bez kontextu model všechny tyto faktory odhaduje, což vede k překladům, které jsou technicky správné, ale často nevhodné pro skutečnou situaci.
Které jazyky vyžadují gramatický rod v překladu
Většina světově rozšířených jazyků používá gramatický rod do určité míry. Ruština, arabština, hebrejština, hindština, francouzština, španělština, portugalština, italština, němčina, polština, čeština a mnoho dalších vyžaduje shodu rodu ve slovesech, přídavných jménech nebo obojím. Angličtina je spíše výjimkou než pravidlem, a proto jsou problémy s rodem v překladu často neviditelné pro anglické mluvčí, dokud na ně někdo na druhé straně neupozorní.
Mohou AI překladače nahradit lidské překladatele pro rodové jazyky
AI překladače mohou dosahovat vynikajících výsledků v rodových jazycích, pokud dostanou správný kontext. Klíčem je poskytnout kontext, na který by se lidský překladatel přirozeně zeptal: kdo mluví, kdo je publikum, jaká je úroveň formálnosti a jaká je tematika. Bez tohoto kontextu je AI výstup v rodových jazycích nespolehlivý. S ním je výstup často k nerozeznání od profesionálního lidského překladu pro standardní obchodní a osobní komunikaci.
Jaká je nejlepší alternativní aplikace ke Google Překladači
Nejlepší alternativa závisí na tom, co Google Překladač dělá špatně. Pro uživatele, kteří potřebují kontextový výstup s kontrolou nad rodem, formálností a oborovou terminologií, AI textový překladač YEB vyplňuje mezery, které Google ponechává otevřené. Pro profesionální překlad ve velkém objemu nástroje jako DeepL nabízejí silnou kvalitu v evropských jazycích. Srovnání 10 nejlepších AI překladatelských nástrojů poskytuje podrobný rozbor silných a slabých stránek hlavních možností.