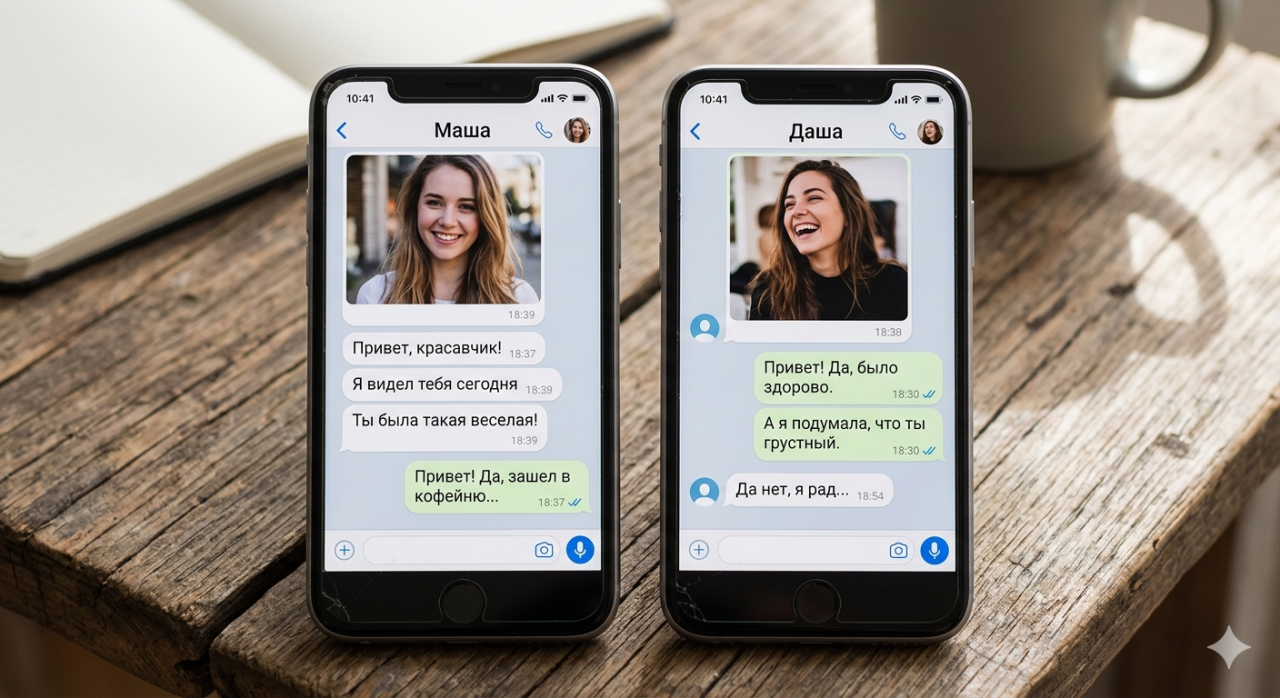
Keskustelu sujui hyvin. Se oli epämuodollinen chat ohjelmistoprojektista, sellaista arkipäiväistä viestien vaihtoa, jota kehittäjien välillä tapahtuu kymmeniä kertoja päivässä eri kieliä puhuvien ihmisten kesken. Toinen henkilö oli venäläinen, viestit kirjoitettiin englanniksi, ja Google-kääntäjä hoiti raskaan työn kääntäen kaiken venäjäksi lennossa. Noin kymmenen viestin ajan kaikki tuntui sujuvan hyvin. Sitten, tyhjästä, venäläinen kirjoitti jotain, joka vapaasti käännettynä kuului: "Hetkinen, oletko mies vai nainen?" Kysymys vaikutti järjettömältä. Mikään keskustelussa ei liittynyt sukupuoleen. Profiilikuvassa ei ollut epäselvyyttä, nimissä ei ollut sekaannusta. Aiheena oli tietokantarakenne. Ja silti toisen henkilön näkökulmasta kysymys oli täysin järkevä.
Venäjä on kieliopillisesti sukupuolitettu kieli. Menneen ajan verbit, adjektiivit ja jopa tietyt substantiivit muuttavat muotoaan puhujan kieliopillisen suvun mukaan. Kun joku kirjoittaa venäjäksi "tein", verbin pääte kertoo lukijalle, onko puhuja mies vai nainen. Google-kääntäjä, joka toimi ilman minkäänlaista kontekstia siitä, kuka kirjoitti, oli valinnut feminiiniset verbimuodot jokaiseen viestiin. Venäjänkieliselle lukijalle näytti tarkalleen siltä kuin nainen kirjoittaisi. Todellinen puhuja oli mies. Kääntäjällä ei ollut mitään tapaa tietää tätä, koska kukaan ei kertonut sille, eikä se koskaan kysynyt.
Tämä ei ollut pieni tyylillinen omituisuus. Koko keskustelun sävy muuttui. Kieliopillinen suku venäjässä ei ole valinnainen koriste. Se on sisäänrakennettu lähes jokaisen lauseen rakenteeseen, joka viittaa puhujaan menneessä ajassa. "Menin kauppaan" sanominen käyttää eri sanaa riippuen siitä, menikö mies vai nainen. "Olin väsynyt" sanominen muuttuu. "Sain projektin valmiiksi" sanominen muuttuu. Jokainen ensimmäisen persoonan menneen ajan lausuma oli lähettänyt väärää identiteettiä koko keskustelun ajan, ja venäläinen osallistuja oli yksinkertaisesti olettanut kääntäjän tulosteen olevan oikein.
Se hetki oli laukaiseva tekijä. Ei ärtymys yksittäisestä käännösvirheestä, vaan oivallus siitä, että planeetan käytetyin käännöstyökalu ei sisällä minkäänlaista mekanismia tietääkseen jotain niin perustavanlaatuista kuin puhujan sukupuoli. Se ei kysy. Se ei päättele. Se valitsee oletuksen ja jatkaa eteenpäin, jättäen lukijan tekemään johtopäätöksiä, jotka voivat olla täysin vääriä. Ratkaisu ei ollut parempi algoritmi. Ratkaisu oli konteksti.
🌐AI-kääntäjä
Käännä, muotoile uudelleen, korjaa ja selitä tekstiä 105+ kielellä. Monikielinen käännös, mukautetut kontekstit ja valintatoiminnot.
Englanti on kieli, joka suurelta osin välttää kieliopillista sukua arkipuheessa. "I went" on "I went" riippumatta siitä, kuka puhuu. "I was happy" ei muutu puhujan identiteetin perusteella. Tämä tekee englanninkielisten helpoksi unohtaa, etteivät useimmat maailman tärkeimmät kielet toimi näin. Venäjä, arabia, heprea, hindi, ranska, espanja, portugali, saksa, puola, tšekki ja kymmenet muut koodaavat kaikki sukupuolen kielioppiinsa vaihtelevassa määrin.
Ongelma konekäännökselle on suoraviivainen. Kun lähdeteksti on englanniksi, ei ole sukupuolen merkkejä poimittavaksi. Lause "I was surprised" antaa kääntäjälle nollatiedon siitä, käytetäänkö maskuliini- vai feminiinimuotoa kohdekielessä. Ihmiskääntäjä kysyisi tai tietäisi aiemmasta kontekstista. Konekääntäjä valitsee sen muodon, joka esiintyi useammin sen harjoitusdatassa, mikä useimmissa kielissä oletusarvoisesti tarkoittaa maskuliinia, joskin ei aina johdonmukaisesti. Google-kääntäjän on havaittu vaihtavan maskuliini- ja feminiinimuotojen välillä yksittäisen kappaleen sisällä, jolloin syntyy tekstiä, joka kuulostaa siltä kuin puhuja olisi vaihtanut sukupuolta kesken keskustelun.
Tämä ei ole reunatapaus, joka vaikuttaa kouralliseen epäselviä kielipareja. Pelkästään venäjällä on yli 250 miljoonaa puhujaa. Arabialla on yli 300 miljoonaa. Espanjalla on yli 500 miljoonaa. Hindillä on yli 600 miljoonaa. Jokaisessa näistä kielistä väärä kieliopillinen suku ei kuulosta vain kömpelöltä. Se aiheuttaa aitoa hämmennystä siitä, kuka puhuu, ja voi heikentää koko viestin uskottavuutta. Liiketoimintaehdotus, joka käyttää vääriä sukupuolitttuneita muotoja, vaikuttaa parhaimmillaan huolimattomalta ja pahimmillaan automatisoidulta. Henkilökohtainen viesti, joka tunnistaa puhujan sukupuolen väärin, on aktiivisesti harhaanjohtava.
YEB Translate -palvelussa toteutettu ratkaisu on käsitteellisesti lähes nolottavan yksinkertainen, vaikka toteutus vaati huolellista suunnittelua. Käännösasetuksissa saatavilla olevista kontekstikategorioista yksi on puhujan sukupuoli. Sen asettaminen kerran kertoo tekoälymallille käyttää oikeita sukupuolitettuja muotoja jokaisessa tulosteessa, jokaisella kielellä, joka sitä vaatii. Sitä ei tarvitse määrittää uudelleen lausekohtaisesti tai kappalekohtaisesti. Konteksti säilyy koko istunnon ajan, ja tuloste kuulostaa siltä kuin se olisi kirjoitettu määritetyn sukupuolen henkilön toimesta tai hänelle aivan ensimmäisestä sanasta alkaen.
Mitä kontekstikategoriat todella tekevät käännökselle
Puhujan sukupuoli on yksi kymmenestä kontekstikategoriasta, jotka muokkaavat tekoälyn käännöstuotantoa. Koko setti kattaa toimialan, kohdeyleisön, muodollisuustason, rekisterin, sävyn, tarkoituksen, alan terminologian, puhujan sukupuolen, alueellisen variantin ja aiheen. Jokaisessa kategoriassa on useita vaihtoehtoja. Pelkästään toimiala tarjoaa vaihtoehtoja teknologiasta ja rahoituksesta terveydenhuoltoon, lakiin, markkinointiin, koulutukseen ja muuhun. Muodollisuus kattaa viisi tasoa erittäin epämuodollisesta erittäin muodolliseen. Yhdessä nämä kymmenen kategoriaa sisältävät 117 yksittäistä vaihtoehtoa, jotka voidaan yhdistää kuvaamaan minkä tahansa käännöstehtävän tarkkaa kontekstia.
Näiden lisäksi on 22 kieliasetusta 78 vaihtoehdolla, jotka ohjaavat yksittäisten kielten kielellisiä yksityiskohtia. Asioita kuten käytetäänkö muodollista vai epämuodollista "sinä"-muotoa kielissä, jotka erottavat nämä toisistaan, mikä koskee lähes jokaista eurooppalaista kieltä paitsi englantia. Suositaanko latinalaista vai kyrillistä kirjoitusta serbiassa. Käytetäänkö yksinkertaistettuja vai perinteisiä kiinalaisia merkkejä. Nämä asetukset eivät koske sitä, mitä sanotaan. Ne koskevat sitä, miten se sanotaan, yksityiskohtien tasolla, jota geneeriset käännöstyökalut eivät yksinkertaisesti tarjoa.
Kaikki nämä asetukset litistetään yhdeksi kontekstimerkkijonoksi, joka liitetään jokaiseen käännöspyyntöön. Tekoälymalli lukee tämän kontekstin ennen kuin se käsittelee lähdetekstin, mikä tarkoittaa, että se tietää toimialan, yleisön, sävyn, muodollisuuden ja kyllä, puhujan sukupuolen ennen kuin se tuottaa ainuttakaan sanaa. Tulos ei ole geneerinen käännös, joka sattuu olemaan kieliopillisesti oikein. Se on käännös, joka kuulostaa siltä kuin sen olisi kirjoittanut joku, joka ymmärtää tilanteen, yleisön ja kohdekielen käytännöt. Ero täydellä kontekstilla tehdyn ja ilman kontekstia tehdyn käännöksen välillä on usein niin dramaattinen, että ne näyttävät aivan eri työkaluilla tehdyiltä. Tekoälytekstikääntäjä -sivu käy läpi konkreettisia esimerkkejä kaikille, jotka ovat uteliaita siitä, kuinka erilaisia tulosteet voivat olla.
Keskustelu, joka melkein tuhosi liikesuhteen
Palataksemme alkuperäiseen venäjänkieliseen keskusteluun, seuraukset ulottuivat kiusallisen hetken tuolle puolen. Toisessa päässä oleva henkilö oli käyttänyt kymmenen viestiä rakentaakseen mielikuvan siitä, kenen kanssa hän puhui, ja tuo mielikuva oli väärä. Kun sukupuolikysymys tuli esiin ja korjaus tehtiin, keskustelussa tapahtui huomattava nollaus. Ei vihamielisyyttä, mutta uudelleenkalibrointi. Luottamus, joka oli rakentumassa, oli hieman kolhiintunut, koska viestintäväline oli tuonut mukaan väärää tietoa.
Epämuodollisessa chatissa tämä on hauska anekdootti. Liiketoimintakontekstissa se voi olla aidosti vahingollista. Kuvittele kumppanuusehdotuksen lähettämistä arabiaksi, jossa verbimuodot viittaavat lähettäjän olevan nainen, kun lähettäjä on mies, tai päinvastoin. Vastaanottaja ei ehkä sano mitään, mutta huomaa sen, ja jäljelle jäävä vaikutelma on, ettei lähettäjä joko ymmärrä kieltä, jolla väittää kommunikoivansa, tai käyttää heikkolaatuisia automatisoituja työkaluja. Kumpikaan vaikutelma ei auta kaupan sulkemisessa.
Sama periaate pätee asiakaspalveluvuorovaikutuksiin, juridiseen viestintään, lääketieteelliseen kirjeenvaihtoon ja mihin tahansa tilanteeseen, jossa puhujan identiteetillä on merkitystä. Sukupuolitetuissa kielissä puhujan identiteetti on koodattu itse kielioppiin. Tämän tiedon poistaminen, tai vielä pahempaa, sen täyttäminen väärin, ei ole neutraali teko. Se vääristää viestiä aktiivisesti. Kunnollisen Google-kääntäjän vaihtoehdon on käsiteltävä tämä, ja sen käsitteleminen tarkoittaa käyttäjälle kontekstin hallinnan antamista, ei sen arvaamista riittämättömästä datasta.
Sukupuolen tuolle puolen: puuttuvan kontekstin koko laajuus
Kieliopillinen suku on näkyvin esimerkki kontekstin epäonnistumisesta käännöksessä, mutta kaukana ainoasta. Otetaan muodollisuus. Japanissa puheeseen koodattu kohteliaisuuden taso voi vaihdella niin dramaattisesti, että sama lause käännettynä eri muodollisuustasoilla ei jaa lähes mitään sanastoa. Saksa erottaa "du" ja "Sie" epämuodollista ja muodollista puhuttelua varten. Ranskassa on "tu" ja "vous". Espanjassa on "tú" ja "usted". Jokaisessa tapauksessa väärän muodollisuustason valitseminen viestii jotain puhujan ja kuuntelijan välisestä suhteesta, ja se jotain voi olla täysin epätarkkaa.
Alan jargon on toinen alue, jossa konteksti on välttämätön. Sana "protokolla" tarkoittaa jotain tiettyä lääketieteessä, jotain muuta verkkotyössä ja jotain aivan muuta diplomatiassa. "Sitoutuminen" markkinoinnissa viittaa käyttäjävuorovaikutusmittareihin. Sotilaallisessa kontekstissa se viittaa taisteluun. Henkilökohtaisessa kontekstissa se viittaa kihlausehdotukseen. Ilman alan kontekstia toimiva kääntäjä valitsee sen merkityksen, jota sen harjoitusdata suosii, ja jos lähdeteksti tulee kapeasta alasta, tulos voi olla täysin väärä.
YEB Translaten käyttöopas kattaa koko asetusprosessin, mukaan lukien kontekstikategorioiden määrittämisen tietyille työnkuluille. Kenelle tahansa, joka on kokenut turhautumista käännöksistä, jotka kuulostavat epämääräisesti oikeilta mutta ohittavat tarkoitetun merkityksen, kontekstijärjestelmä on se puuttuva palanen. Se ei tee tekoälystä älykkäämpää. Se antaa tekoälylle tiedon, jota se tarvitsee älykkäiden valintojen tekemiseen – saman tiedon, jota ihmiskääntäjä pyytäisi ennen työn aloittamista.
Usein kysytyt kysymykset
Käsitteleekö Google-kääntäjä kieliopillisen suvun oikein
Google-kääntäjä ei kysy eikä huomioi puhujan sukupuolta. Käännettäessä englannista sukupuolitettuihin kieliin kuten venäjään, arabiaan tai espanjaan se oletuksena valitsee sen muodon, joka esiintyi useimmin harjoitusdatassa. Tämä voi johtaa väärän sukupuolen käyttämiseen läpi koko keskustelun, mikä aiheuttaa hämmennystä lukijalle ja esittää puhujan identiteetin väärin.
Onko olemassa ilmainen tekoälykääntäjä, joka tukee kontekstiasetuksia
YEB Translate käyttää käyttöperusteista krediittimallia tilauksen sijaan. Krediittejä kulutetaan vain, kun tekstiä todella käsitellään, ja kontekstijärjestelmä kaikkien kymmenen kategorian kanssa on käytettävissä jokaisessa pyynnössä. Kontekstitietoiselle käännökselle ei ole erillistä hinnoittelutasoa.
Mikä on kontekstitietoinen käännös ja miksi sillä on merkitystä
Kontekstitietoinen käännös tarkoittaa, että tekoälymalli saa tietoa puhujasta, yleisöstä, toimialasta, muodollisuustasosta ja muista tekijöistä ennen käännöksen tuottamista. Tämä tieto muokkaa sanavalinnat, kieliopin, sävyn ja rekisterin tulosteessa. Ilman kontekstia malli arvaa kaikki nämä tekijät, mikä johtaa käännöksiin, jotka ovat teknisesti oikeita mutta usein sopimattomia todelliseen tilanteeseen.
Mitkä kielet vaativat kieliopillisen suvun käännöksessä
Useimmat maailman laajasti puhutuista kielistä käyttävät kieliopillista sukua jossain määrin. Venäjä, arabia, heprea, hindi, ranska, espanja, portugali, italia, saksa, puola, tšekki ja monet muut vaativat kaikki sukupuolen yhtäpitävyyttä verbeissä, adjektiiveissa tai molemmissa. Englanti on pikemminkin poikkeus kuin sääntö, minkä vuoksi sukupuoliongelmat käännöksessä ovat usein näkymättömiä englanninkielisille, kunnes joku toisessa päässä huomauttaa niistä.
Voivatko tekoälykääntäjät korvata ihmiskääntäjät sukupuolitetuissa kielissä
Tekoälykääntäjät voivat tuottaa erinomaisia tuloksia sukupuolitetuissa kielissä, kun ne saavat asianmukaisen kontekstin. Avain on tarjota konteksti, jota ihmiskääntäjä luonnollisesti pyytäisi: kuka puhuu, kuka on yleisö, mikä on muodollisuustaso ja mikä on aihe. Ilman tätä kontekstia tekoälyn tuotos sukupuolitetuissa kielissä on epäluotettavaa. Sen kanssa tuotos on usein erottamatonta ammattimaisesta ihmiskäännöksestä tavallisessa liike- ja henkilökohtaisessa viestinnässä.
Mikä on paras vaihtoehtoinen sovellus Google-kääntäjälle
Paras vaihtoehto riippuu siitä, mitä Google-kääntäjä tekee väärin. Käyttäjille, jotka tarvitsevat kontekstitietoista tulostetta halliten sukupuolta, muodollisuutta ja alan terminologiaa, YEB:n tekoälytekstikääntäjä täyttää aukot, jotka Google jättää avoimiksi. Suurivolyymiseen ammattikäännökseen DeepL:n kaltaiset työkalut tarjoavat vahvaa laatua eurooppalaisissa kielissä. 10 parhaan tekoälykäännöstyökalun vertailu tarjoaa yksityiskohtaisen erittelyn tärkeimpien vaihtoehtojen vahvuuksista ja heikkouksista.