Siedemdziesiąt procent mojego ruchu był fałszywy i tak dowiodem go jednym wywołaniem API
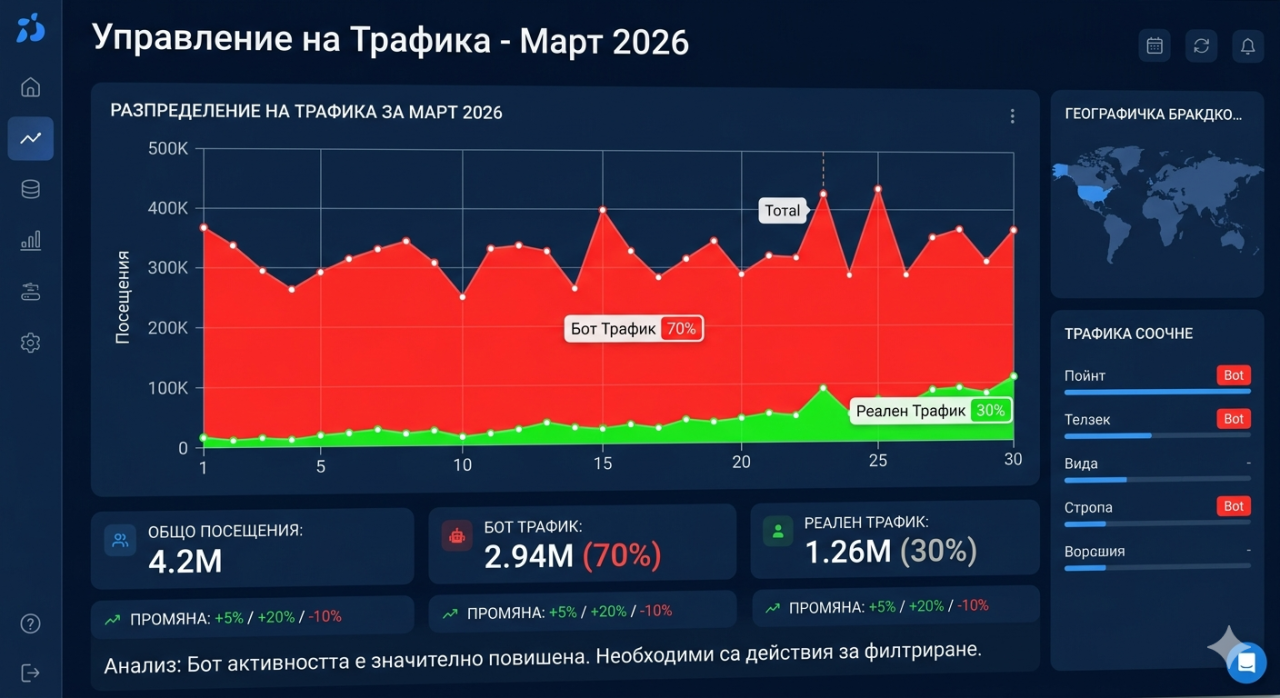
Pulpit analityki pokazywał dziesięć milionów wizyty miesięcznych. Dziesięć milionów. Ta liczba powinna być powodem do radości, i przez jakiś czas była. Wykresy ruchu wskazywały w górę, liczby wyświetleń stron gromadzily się imponująco, a użycie przepustowości odzwierciedlało witrynę, która wydawała się rozkwitać. Ale była trwała, dręcząca niespójność, która odmawiała odejścia. Mierniki zaangażowania opowiadały zupełnie inną historię. Współczynniki odbicia były astronomicznie wysokie. Czasy sesji były podejrzanie krótkie. Współczynniki konwersji były żenujące w stosunku do wielkości ruchu. A rachunki za przepustowość od dostawcy hostingu były zdumiewające, znacznie przekraczające to, co dziesięć milionów ludzi powinno racjonalnie zużywać, ponieważ wiele z tych "odwiedzających" żądało stron w tempie i wzorcu, które żadna ludzka sesja przeglądania nie mogłaby wytworzyć.
Podejrzenie zaczęło się jako cicha intuicja i rosło w przekonanie na przestrzeni miesięcy. Coś było nie tak z ruchem. Dzienniki serwera pokazywały ogromne ilości żądań od agentów użytkownika twierdząc, że są Googlebotem, Bingbotem, crawlerem ChatGPT i różnymi innymi legalnymi botami wyszukiwarek. Na powierzchni wydawało się to normalne. Duża witryna naturalnie przyciąga dużą aktywność crawlera. Ale objętość była nieproporcjonalna, a wzorce zachowań były dziwne. Legalne crawlery przestrzegają dyrektyw robots.txt, rozkładają swoje żądania, aby uniknąć przeciążenia serwera, i pochodzą ze znanych zakresów IP powiązanych z ich odpowiednimi firmami. Dużo tego ruchu nie robił nic z tych rzeczy. Bombardował serwer bezlitośnie, ignorował dyrektywy crawl-delay i pochodził z adresów IP należących do dostawców chmury zamiast Google lub Microsoft.
Ostateczny test był zaskakująco prosty. Weź adres IP żądania, które twierdzi, że jest Googlebotem, i sprawdź, czy faktycznie należy do Google. Prawdziwy Googlebot pochodzi wyłącznie z adresów IP w obrębie autonomicznego systemu Google AS15169. Jeśli żądanie twierdzi, że jest Googlebotem, ale pochodzi z adresu AWS IP, DigitalOcean IP lub jakiegoś adresu IP poza znanymi zakresami Google, jest niepodważalnie fałszywe. Jedno wywołanie API do usługi detekcji botów z adresem IP i ciągiem agenta użytkownika, a wyrok wrócił natychmiast: nie jest legalnym crawlerem Google. Jedno to wywołanie, powtarzane w próbce ruchu, ujawniło, że około siedemdziesiąt procent wszystkich wizyt pochodziło od botów podszywających się pod legalne crawlery. Dziesięć milionów wizyty miesięcznych było bliższe trzem milionom rzeczywistych, a siedem milionów żądań od oszustów zużywających zasoby serwera, podmuchu kosztów przepustowości i zatruwających każdy wskaźnik analityki w procesie.
Moment, w którym liczby przestały mieć sens
Realizacja nie przyszła jako nagłe objawienie. Gromadził się poprzez małe obserwacje na przestrzeni miesięcy. Pierwszą wskazówką był rachunek za przepustowość. Dostawca hostingu pobierał za transfer danych, a miesięczny rachunek rósł stale, nawet jeśli zawartość witryny nie wzrosła proporcjonalnie. Obsługiwano więcej stron, ale zawartość na stronę nie zmieniła się znacząco. Dodatkowe użycie przepustowości było zużywane przez coś, a dzienniki dostępu wskazywały ruch crawlera jako główny czynnik. To wydawało się rozsądne dla witryny tej wielkości, więc obawy zostały odłożone jako koszt prowadzenia działalności.
Drugą wskazówką było obciążenie serwera. Użycie procesora podczas godzin szczytu ruchu było konsekwentnie wyższe niż oczekiwano. Aplikacja była dobrze zoptymalizowana, z buforowaniem na wielu warstwach, a specyfikacja sprzętu powinna obsługiwać ruch komfortowo. Ale średnie obciążenia mówiły inną historię. Serwer pracował ciężko, a dodatkowa praca nie korelowała ze szczytami ruchu skierowanymi do użytkownika, ale ze stałym, całodobowym wolumenem żądań, który nigdy nie spadł do zera. Prawdziwy ruch ludzki podąża przewidywalnymi wzorcami. Osiąga szczyt w godzinach pracy, spada w nocy i zmienia się w zależności od dnia tygodnia. Ruch botów działa dwadzieścia cztery godziny na dobę, siedem dni w tygodniu, ze stałą szybkością, i był widoczny na wykresach obciążenia jako linia bazowa, która nigdy nie spadła poniżej określonego progu.
Trzecią wskazówką i tą, która ostatecznie wyzwoliła śledztwo, była rozbieżność analityki. Google Analytics, które śledzi tylko odwiedzających wykonujących JavaScript, wykazywał znacznie mniej ruchu niż dzienniki serwera. Różnica między dwiema liczbami był ruch botów. Prawdziwe przeglądarki wykonują JavaScript i rejestrują się w analityce. Boty, które żądają stron HTML bez wykonywania JavaScript, pojawiają się w dziennikach serwera, ale nie w analityce. Znaczna luka między dwiema jest silnym wskaźnikiem dużej aktywności botów, a luka na tej witrynie była ogromna.
Uzbrojony w te obserwacje, śledztwo rozpoczęło się na serio. Próbka tysiąca wpisów dziennika dostępu twierdząc, że pochodzą z Googlebota, została wyodrębniona i ich adresy IP sprawdzono względem opublikowanych przez Google zakresów IP. Wynik był druzgotający. Ponad siedemset z tych tysiąc żądań pochodziło z adresów IP, które w ogóle nie miały żadnego związku z Google. Pochodziły z AWS, Hetzner, OVH i różnych innych dostawców hostingu. Ciąg agenta użytkownika powiedział Googlebot, ale adres IP powiedział losowy serwer w centrum danych. Rozszerzenie analizy na Bingbota, crawler ChatGPT i inne twierdzone tożsamości dało podobne wyniki. Ruch był zdecydowanie fałszywy.
Jak jedno wywołanie API weryfikuje tożsamość dowolnego crawlera
Proces weryfikacji, który ujawnił fałszywy ruch, jest koncepcyjnie prosty, ale praktycznie skomplikowany do wdrożenia od podstaw. Każda duża wyszukiwarka i crawler operuje z określonego zestawu zakresów IP związanych z numerem systemu autonomicznego ich firmy. Google używa AS15169. Microsoft używa kilku ASN dla infrastruktury Bing. Crawler OpenAI używa swoich wyznaczonych zakresów. Weryfikacja crawlera oznacza pobranie adresu IP przychodzącego żądania, wykonanie odwrotnego wyszukiwania DNS, potwierdzenie, że domena pasuje do oczekiwanego wzorca, wykonanie przedniego wyszukiwania DNS w celu potwierdzenia, że adres IP pasuje do domeny, i sprawdzenie, czy adres IP mieści się w obrębie oczekiwanego ASN. Ta wieloetapowa weryfikacja łapie wyrafinowane fałszerstwa, które mogą przejść jedno lub dwa testy, ale upadają pełny łańcuch.
API detekcji botów hermetyzuje cały ten łańcuch weryfikacji w jedno wywołanie. Wyślij adres IP i twierdzi agenta użytkownika, a API zwraca orzeczenie: legalne lub fałszywe, wraz z dowodami wspierającymi ustalenie. ASN adresu IP, wynik odwrotnego DNS, oczekiwane ASN dla twierdza tożsamości i poziom pewności oceny. Dla siedemdziesięciu procent ruchu, który był fałszywy, dowód był jednoznaczny. Adresy IP należały do dostawców chmury, odwrotne DNS zwróciło generyczne nazwy hostów, które nie miały nic wspólnego z Google lub Microsoft, a ASN był całkowicie błędny dla twierdza tożsamości.
To, co czyni to podejście ostatecznym zamiast heurystycznym, jest to, że opiera się na zweryfikowanych danych infrastruktury sieciowej, a nie na analizie behawioralnej. Wyrafinowany bot może naśladować człowiekie wzorce przeglądania, randomizować czasowe żądania, wykonywać JavaScript, a nawet rozwiązywać CAPTCHy. Ale nie może zmienić autonomicznego numeru systemu adresu IP, z którego się łączy. Jeśli żądanie twierdzi, że jest Googlebotem, ale pochodzi z centrum danych AWS, jest fałszywe. Nie ma szarej strefy, brak wyniku prawdopodobieństwa, brak obaw o fałszywe alarmy. Infrastruktura sieci nie kłamie, a API po prostu ujawnia tę prawdę w formacie, który można zużywać programowo.
Co zmieniło się po zidentyfikowaniu fałszywego ruchu
Wiedza, że siedemdziesiąt procent ruchu było fałszywe, natychmiast zmieniła każdą decyzję biznesową opartą na wskaźnikach ruchu. Rzeczywista widownia wyniosła trzy miliony wizyty miesięcznych, a nie dziesięć milionów. Rzeczywisty współczynnik konwersji był ponad trzy razy wyższy niż obliczony, ponieważ mianownik został zawyżony o siedem milionów nieistniejących użytkowników. Prawdziwe wskaźniki zaangażowania były szanowalne zamiast żenujące. Każdy raport, który został wygenerowany, każde spotkanie strategiczne, które odwoływało się do numerów ruchu, każda decyzja planowania zdolności oparta na projekcjach wzrostu, została zbudowana na fundamencie zanieczyszczonych danych. Fałszywy ruch nie tylko zużył zasoby serwera. Zniekształciła całą analytyczną strukturę biznesu.
Natychmiastowe działanie techniczne polegało na wdrożeniu blokowania na poziomie serwera. Każde przychodzące żądanie twierdzone, że jest crawlerem wyszukiwarki, zostało zweryfikowane względem API w czasie rzeczywistym. Żądania, które nie przeszły weryfikacji, zostały zablokowane zanim dotarły do warstwy aplikacji. Efekt był dramatyczny i natychmiastowy. Zużycie przepustowości gwałtownie spadło. Użycie procesora serwera podczas godzin poza szczytem spadło do ułamka poprzedniego poziomu. Czasy odpowiedzi aplikacji poprawiły się, ponieważ serwer nie marnował już zasobów na renderowanie stron dla botów, które nigdy ich nie zaindeksują. Rachunek dostawcy hostingu zmniejszył się proporcjonalnie.
Oczyszczanie analityki zajęło więcej czasu, ale było równie ważne. Dzięki filtrowanemu fałszywemu ruchowi dane analityki stały się wiarygodne po raz pierwszy. Wzorce zachowań użytkowników stały się widoczne bez poziomu szumów aktywności botów. Rzeczywiste trendy ruchu mogły być identyfikowane i korelowane z wysiłkami marketingowymi. Zawartość, która rzeczywiście przyciągała ludzkich odwiedzających, mogła być odróżniona od zawartości, która przyciągała tylko boty. Ta jasność przekształciła podejmowanie decyzji z domysłów opartych na zanieczyszczonych danych na analizę opartą na rzeczywistości.
Skala problemu w całym Internecie
To doświadczenie nie było odosobnionym przypadkiem. Szacunki branżowe stale umieszczają ruch botów na trzydzieści do pięćdziesięciu procent całego ruchu internetowego na świecie, a dla poszczególnych witryn proporcja może być znacznie wyższa. Witryny z dużymi liczbami stron, wysokim urzędem domeny lub cenną zawartością przyciągają ruch botów nieproporcjonalnie. Scrapery, fałszywe crawlery, boty analizy konkurencji, boty monitorowania cen, boty analiz SEO i różne rodzaje złośliwej automatyzacji przyczyniają się do całkowitego. Większość operatorów witryn nie ma widoczności tego ruchu, ponieważ polegają na narzędziach analitycznych, które mierzą tylko odwiedzających wykonujących JavaScript, pozostawiając całą warstwę botów niewidoczną.
Wpływ finansowy wykracza poza koszty przepustowości. Platformy reklamowe pobierają opłaty na podstawie wyświetleń i kliknięć. Jeśli ruch botów generuje wyświetlenia reklam, te wyświetlenia zawyżają liczby i zniekształcają metryki wydajności kampanii. Ramy testowania A/B, które obejmują wizyty botów w swojej próbce, dają zawodne wyniki. Ograniczanie szybkości i systemy detekcji nadużyć skalibrowane względem całkowitego ruchu będą nieprawidłowo ustawione, jeśli większość tego ruchu nie jest ludzka. Nawet strategia SEO może być zainfekowana, ponieważ dzienniki serwera pokazujące dużą aktywność crawlingu mogą być błędnie interpretowane jako dowód, że wyszukiwarki głębokie indeksują witrynę, podczas gdy w rzeczywistości crawlery są fałsze, a rzeczywiste wyszukiwarki przydzielają znacznie mniejszy budżet crawlingu.
Usługa detekcji botów została całkowicie zrodzona z tego doświadczenia. Logika weryfikacji, która została zbudowana do czyszczenia ruchu jednej witryny, została uogólniona do API, którego każda witryna może używać do weryfikacji tożsamości crawlerów. Osiem specjalnych detektorów obejmujących Google, Bing, OpenAI, Yandex, DuckDuckGo, Qwant i Seznam zapewniają ukierunkowaną weryfikację dla najczęściej podszywanych crawlerów. Rezultatem jest to, że każdy operator witryny może przeprowadzić to samo śledztwo, które ujawniło liczbę siedemdziesiąt procent fałszywego ruchu, a większość odkryje, że ich własne liczby są podobnie zawyżone. Pierwszym krokiem do naprawienia problemu jest udowodnienie, że istnieje, a ten dowód jest odległy o jedno wywołanie API.
Frequently Asked Questions
Jak mogę stwierdzić, czy moja witryna ma znaczny fałszywy ruch botów?
Porównaj dzienniki dostępu serwera względem analityki opartej na JavaScript. Duża luka między dwiema liczbami wskazuje na znaczną aktywność botów. Dodatkowo sprawdź adresy IP żądań twierdźących pochodzenia z wyszukiwarek. Jeśli wiele pochodzi z dostawców chmury zamiast oczekiwanych sieci firmowych, są fałszywe.
Jaka jest różnica między prawdziwym Googlebotem a fałszywym?
Real Googlebot pochodzi wyłącznie z adresów IP w obrębie autonomicznego systemu Google AS15169. Fałszywy Googlebot używa tego samego ciągu agenta użytkownika, ale łączy się z adresów IP należących do dostawców chmury, takich jak AWS, DigitalOcean lub Hetzner. Ciąg agenta użytkownika jest banalnie łatwy do podrobienia, ale adres IP ujawnia prawdziwą pochodzenie.
Czy blokowanie fałszywych botów wpłynie na moje pozycje w wyszukiwarce?
Nie. Blokowanie fałszywych botów dotyczy tylko żądań z adresów IP, które nie należą do legalnej wyszukiwarki. Prawdziwy Googlebot, Bingbot i inne legalne crawlery będą nadal normalnie uzyskiwać dostęp do witryny, ponieważ przechodzą weryfikację. Zablokowane są tylko oszuści.
Ile przepustowości można zaoszczędzić blokując fałszywy ruch botów?
Oszczędności zależy od proporcji fałszywego ruchu. Witryny z dużą fałszywą aktywnością botów zwykle widzą redukcje przepustowości czterdzieści do sześćdziesięciu procent po wdrożeniu weryfikacji i blokowania. Dla witryn z wysokimi kosztami przepustowości może to przełożyć się na znaczne miesięczne oszczędności.
Czy fałszywe boty mogą wykonywać JavaScript i pojawiać się w Google Analytics?
Niektóre wyrafinowane boty rzeczywiście wykonują JavaScript, co oznacza, że mogą pojawić się w narzędziach analitycznych. Jednak większość fałszywych crawlerów to proste generatory żądań HTTP, które nie renderują JavaScript. Weryfikacja oparta na IP łapie oba typy, ponieważ nie opiera się na analizie behawioralnej, ale na zweryfikowanym pochodzeniu sieci żądania.
Jak API detekcji botów obsługuje nowe lub nieznane crawlery?
API zawiera specjalnych detektorów dla ośmiu najczęściej podszywanych crawlerów. W przypadku nieznanych agentów użytkownika API dostarcza informacji ASN i dane odwrotnego DNS, które pozwalają wywołującemu dokonać własnego ustalenia. Zasada ogólna stosuje się uniwersalnie: weryfikuj adres IP względem znanej infrastruktury twierdza tożsamości.