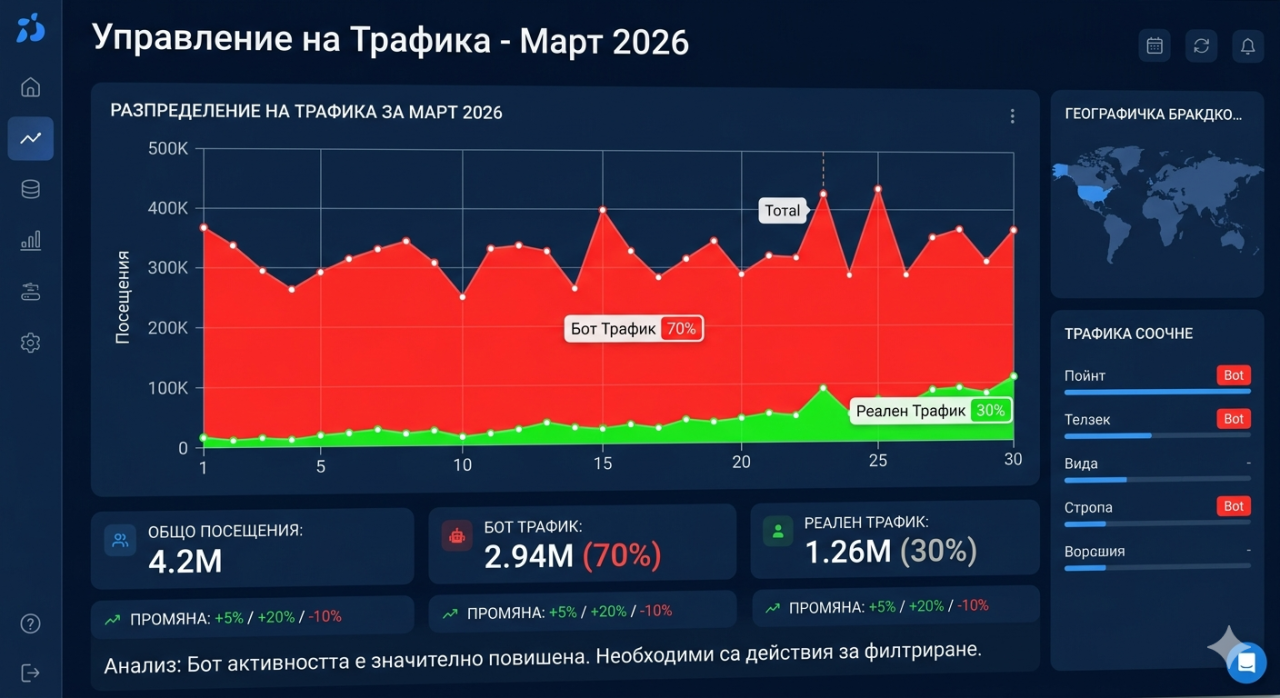
Il settanta percento del mio traffico era falso, e così ho provato con una singola chiamata API
Il dashboard analitico ha mostrato dieci milioni di visite mensili. Dieci milioni. Quel numero avrebbe dovuto essere motivo di celebrazione, e per un po 'lo è stato. I grafici del traffico puntavano verso l'alto, i conteggi delle visualizzazioni di pagina si accumulavano in modo impressionante e l'utilizzo della larghezza di banda rifletteva un sito che sembrava prosperare. Ma c'era una persistente e fastidiosa incoerenza che si rifiutava di scomparire. Le metriche di coinvolgimento hanno raccontato una storia completamente diversa. I tassi di rimbalzo erano astronomicamente alti. Le durate delle sessioni erano sospettosamente brevi. I tassi di conversione erano terribili rispetto al volume del traffico. E le bollette della larghezza di banda del provider di hosting erano sbalorditive, superavano di gran lunga ciò che dieci milioni di visitatori umani dovrebbero ragionevolmente consumare, perché molti di questi "visitatori" richiedevano pagine a una velocità e a un modello che nessuna sessione di navigazione umana avrebbe mai prodotto.
Il sospetto è iniziato come una semplice intuizione ed è cresciuto fino a diventare una convinzione nel corso dei mesi. Qualcosa nel traffico era sbagliato. I registri del server hanno mostrato enormi volumi di richieste da agenti utente che affermavano di essere Googlebot, Bingbot, il crawler di ChatGPT e vari altri legittimi crawler di motori di ricerca. In apparenza, sembrava normale. Un sito di grandi dimensioni attrae naturalmente una pesante attività di crawler. Ma il volume era sproporzionato e i modelli di comportamento erano strani. I veri crawler rispettano le direttive robots.txt, distanziano le loro richieste per evitare di sovraccaricare il server e provengono da intervalli IP noti associati alle loro rispettive aziende. Gran parte di questo traffico non ha fatto nulla di tutto ciò. Ha martellato il server spietatamente, ha ignorato le direttive di ritardo della scansione ed è provenuto da indirizzi IP appartenenti a provider di hosting cloud piuttosto che a Google o Microsoft.
Il test definitivo era sorprendentemente semplice. Prendi l'indirizzo IP di una richiesta che sostiene di essere Googlebot e verifica se appartiene effettivamente a Google. Il vero Googlebot proviene esclusivamente da indirizzi IP all'interno del sistema autonomo di Google, AS15169. Se una richiesta sostiene di essere Googlebot ma proviene da un indirizzo IP di AWS, o da un indirizzo DigitalOcean, o da qualsiasi IP al di fuori degli intervalli noti di Google, è inequivocabilmente falsa. Una singola chiamata all'API di rilevamento bot con l'indirizzo IP e la stringa dell'agente utente, e il verdetto è tornato istantaneamente: non è un vero crawler di Google. Quella singola chiamata, ripetuta su un campione del traffico, ha rivelato che circa il settanta percento di tutte le visite proveniva da bot che si fingevano crawler legittimi. I dieci milioni di visite mensili erano più vicini a tre milioni di veri visitatori, e sette milioni di richieste da impostori che consumano risorse del server, gonfiavano i costi della larghezza di banda e inquinavano ogni metrica di analisi nel processo.
Il momento in cui i numeri hanno smesso di avere senso
La realizzazione non è arrivata come un'epifania improvvisa. Si è accumulata attraverso piccole osservazioni nel corso di mesi. Il primo indizio è stato il conto della larghezza di banda. Il provider di hosting ha addebitato il trasferimento dati e la bolletta mensile stava aumentando costantemente anche se il contenuto del sito non era cresciuto proporzionalmente. Venivano servite più pagine, ma il contenuto per pagina non era cambiato in modo significativo. La larghezza di banda aggiuntiva veniva consumata da qualcosa, e i registri di accesso indicavano il traffico del crawler come driver principale. Questo sembrava ragionevole per un sito di queste dimensioni, quindi la preoccupazione è stata accantonata come un costo per fare affari.
Il secondo indizio è stato il carico del server. L'utilizzo della CPU durante le ore di traffico di picco era costantemente superiore al previsto. L'applicazione era ben ottimizzata, con cache su più livelli, e la specifica hardware dovrebbe aver gestito il traffico comodamente. Ma le medie di carico hanno detto una storia diversa. Il server stava lavorando duro, e il lavoro aggiuntivo non era correlato ai picchi di traffico rivolti agli utenti ma a un volume di richiesta sostenuto, ventiquattro ore su ventiquattro, che non è mai sceso a zero. Il traffico umano reale segue modelli prevedibili. Raggiunge il picco durante le ore lavorative, scende di notte e varia in base al giorno della settimana. Il traffico bot funziona ventiquattro ore al giorno, sette giorni alla settimana, a una velocità costante, ed era visibile nei grafici di carico come una linea di base che non scendeva mai sotto una certa soglia.
Il terzo indizio, e quello che ha infine innescato l'indagine, è stata la discrepanza nelle analisi. Google Analytics, che traccia solo i visitatori che eseguono JavaScript, ha mostrato un traffico sostanzialmente inferiore rispetto ai registri di accesso al server. La differenza tra i due numeri era il traffico bot. I browser reali eseguono JavaScript e si registrano nelle analisi. I bot che richiedono pagine HTML senza eseguire JavaScript compaiono nei registri del server ma non nelle analisi. Un divario significativo tra i due è un forte indicatore di una pesante attività bot, e il divario su questo sito era enorme.
Armati di queste osservazioni, l'indagine è iniziata sul serio. Un campione di mille voci del registro di accesso che affermavano di provenire da Googlebot è stato estratto e i loro indirizzi IP sono stati verificati rispetto agli intervalli IP pubblicati da Google. Il risultato è stato devastante. Più di settecento di queste mille richieste provenivano da indirizzi IP che non avevano alcun rapporto con Google. Provenivano da AWS, Hetzner, OVH e vari altri provider di hosting. La stringa dell'agente utente diceva Googlebot, ma l'indirizzo IP diceva server casuale in un data center. L'estensione dell'analisi a Bingbot, al crawler di ChatGPT e ad altre identità rivendicate ha prodotto risultati simili. Il traffico era schiacciante falso.
Come una singola chiamata API verifica l'identità di qualsiasi crawler
Il processo di verifica che ha rivelato il traffico falso è concettualmente semplice ma praticamente tedioso da implementare da zero. Ogni grande motore di ricerca e crawler opera da una serie specifica di intervalli IP legati al numero del sistema autonomo dell'azienda. Google utilizza AS15169. Microsoft utilizza diversi ASN per l'infrastruttura di Bing. Il crawler di OpenAI utilizza intervalli designati propri. Verificare un crawler significa prendere l'indirizzo IP della richiesta in arrivo, eseguire una ricerca DNS inversa, confermare che il dominio corrisponde al modello previsto, eseguire una ricerca DNS in avanti per confermare che l'IP corrisponde al dominio, e verificare se l'IP rientra nell'ASN previsto. Questa verifica in più fasi cattura sofisticati falsi che potrebbero superare uno o due controlli ma fallire nella catena completa.
L'API di rilevamento bot incapsula l'intera catena di verifica in una singola chiamata. Invia l'indirizzo IP e la stringa dell'agente utente rivendicato, e l'API restituisce un verdetto: legittimo o falso, insieme alle prove a sostegno della determinazione. L'ASN dell'indirizzo IP, il risultato DNS inverso, l'ASN previsto per l'identità rivendicata e il livello di confidenza della valutazione. Per il settanta percento del traffico che era falso, le prove erano inequivocabili. Gli indirizzi IP appartenevano ai provider di hosting cloud, il DNS inverso restituiva nomi di host generici che non avevano nulla a che fare con Google o Microsoft, e l'ASN era completamente sbagliato per l'identità rivendicata.
Ciò che rende questo approccio definitivo piuttosto che euristico è che si basa su dati di infrastruttura di rete verificabili, non sull'analisi del comportamento. Un bot sofisticato può imitare i modelli di navigazione umani, randomizzare i tempi delle richieste, eseguire JavaScript e persino risolvere CAPTCHA. Ma non può cambiare il numero del sistema autonomo dell'indirizzo IP da cui si connette. Se una richiesta sostiene di essere Googlebot ma ha origine da un data center di AWS, è falsa. Non ci sono aree grigie, nessun punteggio di probabilità, nessuna preoccupazione per falsi positivi. L'infrastruttura di rete non mente, e l'API semplicemente espone quella verità in un formato che può essere consumato programmaticamente.
Cosa è cambiato dopo l'identificazione del traffico falso
Sapere che il settanta percento del traffico era falso ha immediatamente cambiato ogni decisione commerciale che era stata basata su metriche di traffico. Il vero pubblico era tre milioni di visitatori mensili, non dieci milioni. Il vero tasso di conversione era più di tre volte superiore al tasso calcolato, perché il denominatore era stato gonfiato da sette milioni di utenti inesistenti. Le vere metriche di coinvolgimento erano rispettabili piuttosto che imbarazzanti. Ogni rapporto che era stato generato, ogni riunione strategica che aveva fatto riferimento ai numeri del traffico, ogni decisione di pianificazione della capacità che era stata basata su proiezioni di crescita era costruita su una base di dati inquinati. Il traffico falso non aveva solo consumato le risorse del server. Aveva distorto l'intero framework analitico dell'azienda.
L'azione tecnica immediata è stata implementare il blocco a livello di server. Ogni richiesta in arrivo che affermava di essere un crawler di motore di ricerca è stata verificata rispetto all'API in tempo reale. Le richieste che non hanno superato la verifica sono state bloccate prima di raggiungere il livello dell'applicazione. L'effetto è stato drammatico e immediato. Il consumo di larghezza di banda è sceso bruscamente. L'utilizzo della CPU del server durante le ore non di punta è sceso a una frazione del suo livello precedente. I tempi di risposta dell'applicazione sono migliorati perché il server non stava più sprecando risorse nel rendering di pagine per bot che non le avrebbero mai indicizzate. La bolletta di hosting è diminuita proporzionalmente.
La pulizia analitica ha richiesto più tempo ma è stata altrettanto importante. Con il traffico falso filtrato, i dati di analisi sono diventati affidabili per la prima volta. I modelli di comportamento degli utenti sono diventati visibili senza il rumore di fondo dell'attività bot. Le tendenze di traffico reali potevano essere identificate e correlate con gli sforzi di marketing. Il contenuto che stava effettivamente attirando i visitatori umani poteva essere distinto dal contenuto che stava solo attirando bot. Questa chiarezza ha trasformato il processo decisionale da congetture basate su dati inquinati ad analisi basate sulla realtà.
L'entità del problema su Internet
Questa esperienza non è un'anomalia. Le stime del settore collocano costantemente il traffico bot tra il trenta e il cinquanta percento di tutto il traffico Internet a livello globale, e per i singoli siti la proporzione può essere molto più elevata. I siti con grandi quantità di pagine, elevata autorità di dominio o contenuto prezioso attirano il traffico bot in modo sproporzionato. Scraper, falsi crawler, bot di intelligence competitiva, bot di monitoraggio dei prezzi, bot di analisi SEO e vari sapori di automazione dannosa contribuiscono tutti al totale. La maggior parte degli operatori di siti non ha visibilità su questo traffico perché si affidano a strumenti di analisi che misurano solo i visitatori che eseguono JavaScript, lasciando l'intero livello bot invisibile.
L'impatto finanziario si estende oltre i costi della larghezza di banda. Le piattaforme pubblicitarie addebitano in base a impressioni e clic. Se il traffico bot genera impressioni pubblicitarie, queste impressioni gonfiano i numeri e distorcono le metriche di prestazioni della campagna. I framework di test A/B che includono visite di bot nel loro campione producono risultati inaffidabili. I sistemi di limitazione della velocità e di rilevamento degli abusi calibrati rispetto al traffico totale saranno sintonizzati in modo errato se la maggior parte di quel traffico non è umano. Anche la strategia SEO può essere influenzata, poiché i registri del server che mostrano un'attività crawler pesante potrebbero essere scambiati per prove che i motori di ricerca stiano indicizzando profondamente il sito, quando in realtà i crawler sono falsi e i veri motori di ricerca stanno allocando un budget di scansione molto più piccolo.
Il servizio di rilevamento bot è nato direttamente da questa esperienza. La logica di verifica che è stata costruita per pulire il traffico di un sito è stata generalizzata in un'API che qualsiasi sito può utilizzare per verificare le identità dei crawler. Gli otto rilevatori specifici che coprono Google, Bing, OpenAI, Yandex, DuckDuckGo, Qwant e Seznam forniscono una verifica mirata per i crawler più comunemente impersonati. Il risultato è che qualsiasi operatore di sito può eseguire la stessa indagine che ha rivelato la cifra del traffico falso del settanta percento, e la maggior parte di loro scoprirà che i loro stessi numeri sono allo stesso modo gonfiati. Il primo passo verso la risoluzione del problema è provare che esiste, e quella prova è a una singola chiamata API di distanza.
Domande frequenti
Come posso sapere se il mio sito ha traffico bot falso significativo?
Confronta i registri di accesso del server rispetto alle analisi basate su JavaScript. Un grande divario tra i due numeri indica un'attività bot sostanziale. Inoltre, controlla gli indirizzi IP delle richieste che affermano di provenire da motori di ricerca. Se molti provengono da provider di hosting cloud anziché dalle reti aziendali previste, sono falsi.
Qual è la differenza tra un vero Googlebot e uno falso?
Il vero Googlebot proviene esclusivamente da indirizzi IP all'interno del sistema autonomo di Google AS15169. Il falso Googlebot usa la stessa stringa dell'agente utente ma si connette da indirizzi IP di proprietà di provider di hosting cloud come AWS, DigitalOcean o Hetzner. La stringa dell'agente utente è banale da falsificare, ma l'indirizzo IP rivela la vera origine.
Il blocco dei bot falsi influirà sui miei ranking nei motori di ricerca?
No. Il blocco dei bot falsi influisce solo sulle richieste provenienti da indirizzi IP che non appartengono al motore di ricerca legittimo. Il vero Googlebot, Bingbot e altri crawler legittimi continueranno ad accedere al sito normalmente perché superano il controllo di verifica. Solo gli impostori vengono bloccati.
Quanta larghezza di banda può essere risparmiata bloccando il traffico bot falso?
I risparmi dipendono dalla proporzione di traffico falso. I siti con una pesante attività bot falsa comunemente vedono riduzioni della larghezza di banda dal quaranta al sessanta percento dopo l'implementazione della verifica e del blocco. Per i siti con elevati costi di larghezza di banda, questo può tradursi in risparmi mensili significativi.
I bot falsi possono eseguire JavaScript e comparire in Google Analytics?
Alcuni bot sofisticati eseguono JavaScript, il che significa che possono apparire negli strumenti di analisi. Tuttavia, la stragrande maggioranza dei crawler falsi sono semplici generatori di richieste HTTP che non eseguono il rendering di JavaScript. La verifica basata su IP rileva entrambi i tipi perché non si basa sull'analisi del comportamento ma sull'origine di rete verificabile della richiesta.
Come gestisce l'API di rilevamento bot i crawler nuovi o sconosciuti?
L'API include rilevatori specifici per gli otto crawler più comunemente impersonati. Per agenti utente sconosciuti, l'API fornisce informazioni ASN e dati DNS inversi che consentono al chiamante di fare la propria determinazione. Il principio generale si applica universalmente: verificare l'indirizzo IP rispetto all'infrastruttura nota dell'identità rivendicata.