שבעים אחוז מהתנועה שלי היו זויפות, וכך הוכחתי זאת בקריאת API אחת
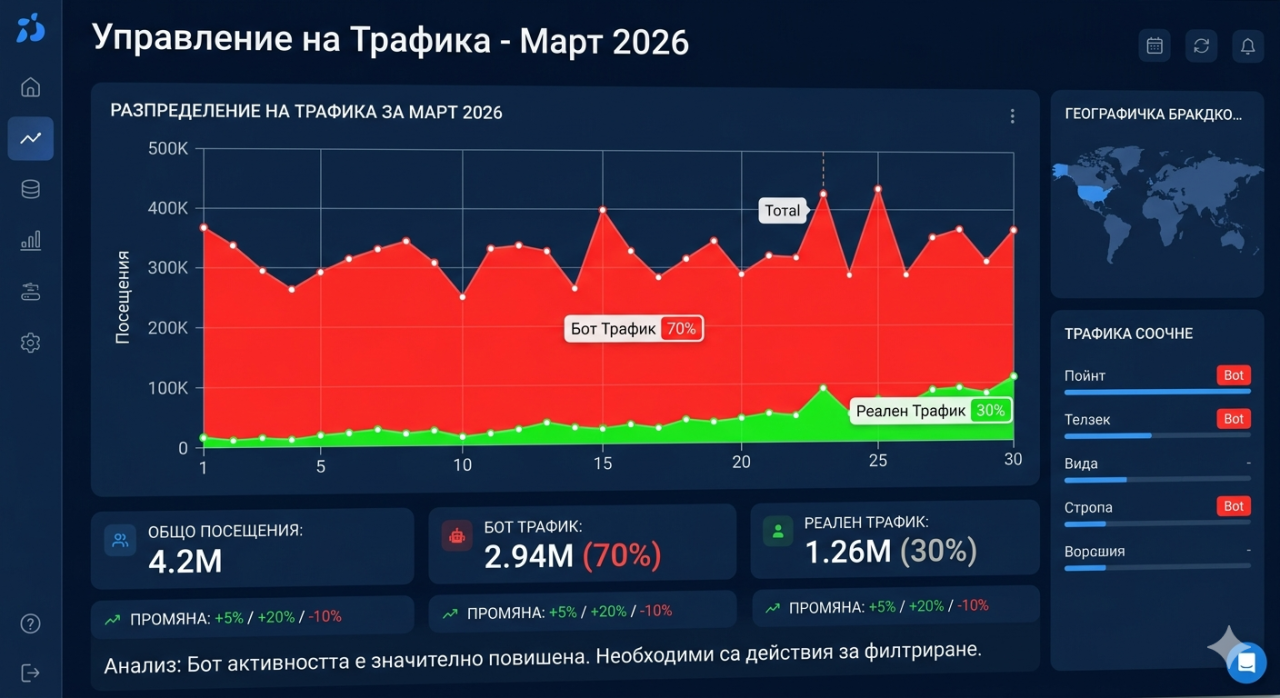
לוח המחוונים של האנליטיקה הראה עשרה מיליון ביקורים חודשיים. עשרה מיליון. המספר הזה היה אמור להיות סיבה לחגיגה, ובתחילה כן היה. גרפי התנועה הצביעו כלפי מעלה, ספירות הצפיות בעמודים הצטברו בהשפעה רבה, וספירת רוחב הפס השתקפה בחיבור הגדל. אך היה אי-עקביות מתמשכת וכוד"ח שסירבה להעלם. מטרי ההעסקה סיפרו סיפור שונה לחלוטין. שיעורי ההקפצה היו גבוהים באופן אסטרונומי. משכי המושב היו חשודים בקיצור. שיעורי ההמרה היו נוראים ביחס לכמות התנועה. וחשבונות רוחב הפס של ספק ההוסטינג היו מדהימים, חורגים בהרבה מעבר למה שעשרה מיליון מבקרים אנושיים צריכים להשקיע בצורה סבירה, משום שרבים מ"המבקרים" הללו ביקשו עמודים בקצב ובתבנית שלא הייתה מייצרת שום הפעלה אנושית בדוק.
החשד החל כהשכלה שקטה וגדל לכל כך מוזר ודברים משונים. משהו בתנועה היה לא בסדר. יומני השרתים הראו כמויות ענק של בקשות מסוכנים משתמש שטענו שהם Googlebot, Bingbot, הזוחל של ChatGPT וקראולרים אחרים חוקיים של מנוע חיפוש. על פני השטח, זה נראה רגיל. אתר גדול בטבע משך פעילות קראולר כבדה. אך ההיקף היה חסר פרופורציות, ודפוסי ההתנהגות היו מוזרים. קראולרים אמיתיים מצייתים להנחיות robots.txt, מרווחים את בקשותיהם כדי להימנע מהיציא את השרת, ומגיעים מטווחי IP ידועים הקשורים לחברות בהן הם קשורים. רוב הסחר הזה לא עשה שום דבר מאלה. זה הלם את השרת ללא רחמים, התעלם מהנחיות הצעדה של הזחילה, והמקור מכתובות IP שהשתייכו לספקי אחסון ענן ולא לגוגל או מיקרוסופט.
הבדיקה ההגדרתית הייתה פשוטה באופן מפתיע. קחו את כתובת ה-IP של בקשה שטוענת להיות Googlebot ובדקו אם היא בעצם שייכת לגוגל. Googlebot אמיתי מגיע אך ורק מכתובות IP בתוך המערכת האוטונומית של גוגל, AS15169. אם בקשה טוענת להיות Googlebot אך מגיעה מכתובת IP של AWS, או כתובת DigitalOcean, או כל IP מחוץ לטווחי גוגל הידועים, היא בהחלט זויפת. קריאה אחת ל-API לשירות גילוי בוט עם כתובת ה-IP ומחרוזת סוכן המשתמש, והגזר חזר מיד: לא קראולר גוגל לגיטימי. קריאה יחידה זו, שחוזרת על דוגמה של התנועה, חשפה שכ-שבעים אחוז מכל הביקורים היו מבוטים המתחזים לקראולרים לגיטימיים. עשרה מיליון ביקורים חודשיים היו קרובים יותר לשלושה מיליון אמיתיים, ושבעה מיליון בקשות מחיקויות הצוכלים משאבים שרתיים, מנופחים עלויות רוחב פס, וזיהמים כל מדד אנליטיקה בתהליך.
הרגע שהמספרים הפסיקו להיות הגיוניים
ההתחייה לא הגיעה כהשכלה פתאומית. זה הצטבר מתצפיות קטנות לאורך חודשים. הרמז הראשון היה חשבון רוחב הפס. ספק ההוסטינג גבה עבור העברת נתונים, וחשבון חודשי עלה בקביעות גם כאשר התוכן באתר לא גדל פרופורציונלית. יותר דפים הוגשו, אך התוכן לדף לא שונה משמעותית. רוחב הפס נוסף צורך משהו, וכניסות הגישה הצביעו על תנועת קראולר כנהג ראשוני. זה נראה סביר לאתר בגודל זה, אז ההשגחה הוגדרה בצד כעלות של עסקים.
הרמז השני היה עומס השרת. שימוש במעבד במהלך שעות תנועה שיא היה עקבי גבוה יותר מהצפוי. היישום היה מיטבי היטב, עם זיכרון מטמון ברמות מרובות, וספציפיקציית החומware צריכה להטפל בתנועה בנוח. אך ממוצעי העומס סיפרו סיפור שונה. השרת עבד קשה, והעבודה הנוספת התקבלה לא עם שיאי תנועה פנימה אלא עם בקשה יציבה, סביב השעון שמעולם לא צנחה לאפס. תנועה אנושית אמיתית עוקבת אחר דפוסים צפויים. זה עוקץ במשך שעות עסקים, נוצל בלילה, משתנה לפי יום בשבוע. תנועת בוט פועלת עשרים וארבע שעות ביום, שבע ימים בשבוע, בקצב קבוע, וזה הראה בגרפי העומס כקו בסיס שלא כל פעם צנח מתחת לסף מסוים.
הרמז השלישי, וזה שלבסוף הדליק את החקירה, היה חוסר התאמה בניתוח. Google Analytics, שעוקב רק אחר מבקרים שמבצעים JavaScript, הראה תנועה הרבה פחות משרתי גישה. ההבדל בין שני המספרים היה תנועת בוט. דפדפנים אמיתיים מבצעים JavaScript ונרשמים ב-analytics. בוטים המבקשים עמודי HTML ללא ביצוע JavaScript מופיעים בכניסות שרת אך לא ב-analytics. הפער משמעותי בין השניים הוא מחוון חזק של פעילות בוט כבדה, והפער באתר זה היה ענק.
בעזרת התצפיות הללו, החקירה התחילה ברצינות. דוגמה של אלף ערכי יומן גישה טוענים שהם מ-Googlebot הוצאו ובדקו כתובות ה-IP שלהם כנגד טווחי IP שפרסם גוגל. התוצאה הייתה הרסנית. יותר משבע מאות מבקשות הללו הגיעו מכתובות IP שלא היה להן קשר כלל לגוגל. הם הגיעו מ-AWS, Hetzner, OVH ומספקי אחסון שונים. מחרוזת סוכן המשתמש אמרה Googlebot, אך כתובת ה-IP אמרה שרת אקראי במרכז נתונים. הרחבת הניתוח ל-Bingbot, הזוחל של ChatGPT וזהויות אחרות טענו להביא תוצאות דומות. התנועה הייתה הוגנת באופן חד-משמעי.
כיצד קריאה אחת ל-API מאשרת את הזהות של כל קראולר
תהליך האימות שחשף את התנועה המזויפת הוא מושג פשוט אך מעייף בפועל ליישום מאפס. כל מנוע חיפוש גדול וקראולר פועל מתוך מערך IP ספציפי הקשור למספר המערכת האוטונומית של החברה שלהם. גוגל משתמש ב-AS15169. מיקרוסופט משתמשת במספר ASN בפני עצמו עבור תשתית Bing. זוחל ChatGPT משתמש בטווחים ייעודיים משלו. אימות קראולר פירושו לקחת את כתובת ה-IP של בקשה נכנסת, לבצע חיפוש DNS הפוך, לאשר שהדומיין תואם לתבנית הצפויה, לבצע חיפוש DNS קדימה כדי לאשר את ה-IP תואם את הדומיין, ולבדוק אם ה-IP נופל בתוך ה-ASN הצפוי. אימות ריבוי-שלב זה תופס זיוף מתוחכם שעלול להעביר בדיקה אחת או שתיים אך להיכשל בשרשרת השלמה.
ה-API גילוי בוט משלב את כל שרשרת האימות הזו לתוך קריאה יחידה. שלחו את כתובת ה-IP ואת מחרוזת סוכן המשתמש הטענה, וה-API מחזיר גזר: לגיטימי או זויף, יחד עם הראיות התומכות בקביעה. ה-ASN של כתובת ה-IP, התוצאה ההפוכה של DNS, ה-ASN הצפוי לזהות הטענה, ורמת הביטחון של ההערכה. עבור שבעים אחוז של התנועה שהיתה זויפת, ההוכחות היו חד-משמעית. כתובות ה-IP שייכו לספקי אחסון ענן, ה-DNS ההפוך החזיר שמות מארח גנריים שלא היה להם שום דבר לעשות עם גוגל או מיקרוסופט, וה-ASN היה לא נכון לחלוטין לזהות הטענה.
מה הופך את הגישה הזו להגדרתית ולא היוריסטית היא שהיא מסתמכת על נתוני בנייה רשת מאומתים, לא על ניתוח התנהגות. בוט מתוחכם יכול לחקות דפוסי עיון אנושיים, הימנעות משכ בקשה שלו, ביצוע JavaScript, ואפילו פתרון CAPTCHAs. אך הוא לא יכול לשנות את מספר המערכת האוטונומית של כתובת ה-IP שהוא מתחבר ממנה. אם בקשה טוענת להיות Googlebot אך מתקבלת ממרכז נתונים AWS, היא זויפת. אין אזור אפור, אין ניקוד הסתברות, אין חשש לחיובי כוזב. הרשת של בנייה לא משקרת, וה-API פשוט חשף את האמת הזו בפורמט שניתן לצרוך בעיצוב אלגוריתמי.
מה השתנה לאחר זיהוי התנועה המזויפת
הידע ששבעים אחוז של התנועה היו זויפות שינה מיד את כל החלטות העסקים שהתבססו על מטרי תנועה. הקהל האמיתי היה שלושה מיליון מבקרים חודשיים, לא עשרה מיליון. שיעור ההמרה האמיתי היה יותר משלוש פעמים גבוה מאשר שיעור מחושב, משום שהמכנה היה מנופח על ידי שבעה מיליון משתמשים לא קיימים. מטרי ההעסקה האמיתיים היו כבודים ולא מביישים. כל דוח שהיה מעוצב, כל פגישת אסטרטגיה שהייתה מפנה מספרי תנועה, כל החלטת תכנון קיבולת שנתבססה על תחזוקות גדילה היתה בנויה על בסיס נתונים מלוכלכים. התנועה המזויפת לא רק צרכה משאבים שרתיים. זה זיקק את כל המסגרת הניתוחית של העסק.
הפעולה הטכנית המיידית הייתה ליישם חסימה ברמת השרת. כל בקשה נכנסת שטוענת להיות קראולר של מנוע חיפוש אומתה כנגד ה-API בזמן אמת. בקשות שנכשלו בשאמות נחסמו לפני שהגיעו לשכבת היישום. ההשפעה הייתה דרמטית ומיידית. צריכת רוחב פס ירדה בתחתוניות. שימוש במעבד של השרת במהלך שעות מחוץ לשיא צנח לשבר של הרמה הקודמת שלו. זמני תשובה של היישום שופרו משום שהשרת כבר לא בזבז משאבים בעמודים שרינור לבוטים שלא יעשו אינדקס שלהם. חשבונות האחסון ירדו באופן פרופורציונלי.
הניקוי הניתוח קח יותר זמן אך היה חיוני באותה מידה. עם התנועה המזויפת מסננת, נתוני הניתוח הפכו למהימנים בפעם הראשונה. דפוסי התנהגות של המשתמש הפכו נראים ללא רמת הרעש של פעילות בוט. מגמות תנועה אמיתיות יכלו להיות מזוהות ומקובלות עם מאמצי שיווק. התוכן שהיה לגיטימי משיכת מבקרים אנושיים יכול היה להיות מובחן מהתוכן שהיה משיכת בוטים בלבד. הבהירות הזו הפכה את קבלת ההחלטות מנחש בהנחת נתונים מלוכלכים לניתוח המבוסס על מציאות.
הגודל של הבעיה על האינטרנט
חוות הדעת של התעשייה מציבה כל הזמן את תנועת הבוט בשלוש עשרים עד חמישים אחוז של כל עומס האינטרנט ברחבי העולם, ועבור אתרים בודדים הפרופורציה יכולה להיות הרבה יותר גבוה. אתרים עם דפים, סמכות דומיין גבוהה או תוכן חיוני משיכים בתנועת בוט באופן חסר פרופורציות. מגרדים, קראולרים מזויפים, בוטים של בינה תחרותית, בוטים של ניטור מחיר, בוטים של ניתוח SEO וטעמים שונים של אוטומציה זיקמת הכל לתוך סך הכל. רוב מפעילי האתר אין להם נראות בתנועה זו משום שהם מסתמכים על כלים אנליטיים המודדים רק מבקרים המבצעים JavaScript, ותוך כדי זה השכבה השלמה של הבוט נשאר בלתי נראה.
ההשפעה הכלכלית משתרעת מעבר לעלויות רוחב פס. פלטפורמות פרסום גובות בהנחה של דפי חזון וקליקים. אם תנועת בוט ייצרה חזוני פרסום, חזוני אלה מנופחים את המספרים וזיקק מדדי ביצוע קמפיין. מסגרות בדיקת A/B הכוללות ביקורי בוט בדוגמה שלהם מייצרות תוצאות בלתי אמינות. מערכות הגבלת קצב וזהוי ניצול כיול כנגד עומס תנועה כללי יהיו מתואמת בצורה שגויה אם רוב התנועה אינה אנושית. אפילו אסטרטגיה SEO יכולה להיות משופעת, כאשר יומני שרת המראים פעילות קראולר כבדה עלולים להיות מטעים כראיה שמנועי חיפוש באופן עמוק כללי את האתר, כאשר במציאות הקראולרים הם זיוף והמנועים החיפוש האמיתיים מקצה תקציב זיחול קטן בהרבה.
שירות גילוי הבוט נולד ישירות מחוויה זו. הלוגיקה של אימות שנבנתה כדי לנקות תנועה אתר אחד הייתה מושמת לתוך API שכל אתר יכול להשתמש בו כדי לאמת הזהויות של קראולר. שמונה גלוי ספציפיים המכסים גוגל, Bing, OpenAI, Yandex, DuckDuckGo, Qwant, וSeznám לספק אימות ממוקד עבור הקראולרים המחוקרות בתחזוקה הנפוצות ביותר. התוצאה היא שכל מפעיל אתר יכול להעביר את החקירה הזהה שחשפה נתון התנועה המזויפת בשבעים אחוז, והרוב שלהם יגלו שהמספרים שלהם דומים מנופחים באופן דומה. הצעד הראשון לכיוון תיקון הבעיה הוא הוכחת הימצאותה, והוכחה זו היא סיוע אחד של API בדיוק.
שאלות נשאלות לעתים קרובות
כיצד אוכל לדעת אם לאתר שלי יש תנועת בוט מזויפת משמעותית?
השווה כניסות גישה שרת שלך כנגד ניתוח מבוסס JavaScript. פער גדול בין שני המספרים מצביע על פעילות בוט משמעותית. בנוסף, בדוק כתובות IP של בקשות טוענות מנועי חיפוש. אם רבים מגיעים מספקי אחסון ענן ולא מרשתות חברה צפויות, הם זויפים.
מה ההבדל בין Googlebot אמיתי וזה זויף?
Googlebot אמיתי מגיע אך ורק מכתובות IP בתוך המערכת האוטונומית של גוגל AS15169. Googlebot זויף משתמש באותה מחרוזת סוכן משתמש אך מתחבר מכתובות IP בבעלות ספקי אחסון ענן כמו AWS, DigitalOcean או Hetzner. מחרוזת סוכן המשתמש היא טריוויאלית לזיוף, אך כתובת ה-IP חושפת את המקור האמיתי.
האם חסימת בוטים מזויפים תשפיע על דירוגי מנוע החיפוש שלי?
לא. חסימת בוטים מזויפים משפיעה רק על בקשות מכתובות IP שאינן שייכות למנוע החיפוש הלגיטימי. Googlebot אמיתי, Bingbot וקראולרים לגיטימיים אחרים יוכלו להמשיך בגישה לאתר בשגרה משום שהם עוברים את בדיקת האימות. רק מחיקויות מונחות.
כמה רוחב פס ניתן לחסוך על ידי חסימת תנועת בוט מזויפת?
החיסכון תלוי בפרופורציה של תנועה מזויפת. אתרים עם פעילות בוט מזויפת כבדה רואים בדרך כלל הפחתות רוחב פס של ארבעים עד שישים אחוז לאחר יישום אימות וחסימה. עבור אתרים עם עלויות רוחב פס גבוהות, זה יכול להתרגם לחסכון חודשי משמעותי.
האם בוטים מזויפים יכולים לבצע JavaScript ולהופיע ב-Google Analytics?
כמה בוטים מתוחכמים מבצעים JavaScript, מה שמשמע שהם יכולים להופיע בכלי ניתוח. עם זאת, רוב קראולרים מזויפים הם מחוללי בקשות HTTP פשוטים שאינם עורכים JavaScript. אימות מבוסס IP תופס שני הטיפים משום שהוא אינו מסתמך על ניתוח התנהגות אלא על מקור הרשת המוודה של הבקשה.
כיצד API גילוי בוט מטפל בקראולרים חדשים או לא ידועים?
ה-API כולל מגלים ספציפיים לשמונה קראולרים המחוקרות השכיחות ביותר. עבור סוכנים משתמש לא ידועים, ה-API מספק מידע ASN וקודים DNS הפוך המאפשרים לקורא לעשות את הקביעה שלהם. העיקרון הכללי חל באופן אוניברסלי: אמת כתובת IP כנגד הרשתות הידועות של זהות הטענה.