Siebzig Prozent meines Verkehrs waren gefälscht, und so habe ich es mit einem API-Aufruf bewiesen
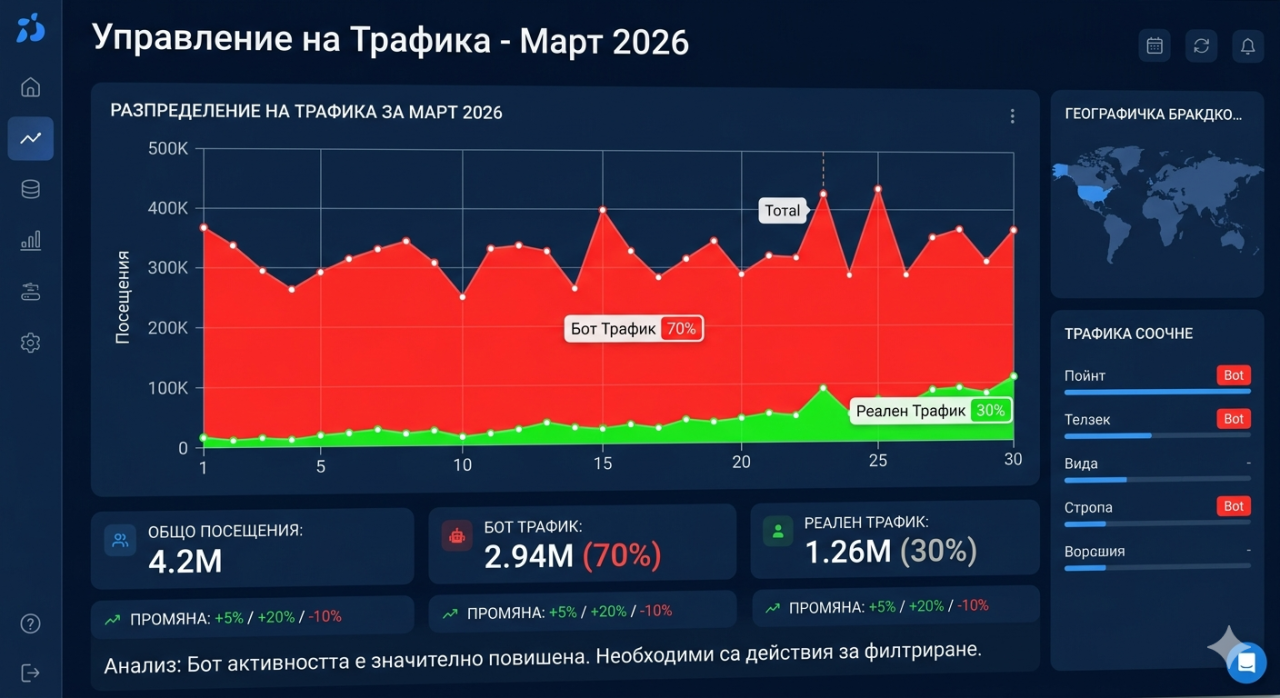
Das Analytics-Dashboard zeigte zehn Millionen monatliche Besuche. Zehn Millionen. Diese Zahl hätte ein Grund zur Freude sein sollen, und das war sie eine Zeit lang. Die Verkehrsdiagramme zeigten nach oben, die Seitenaufrufe sammelten sich beeindruckend an, und die Bandbreitennutzung spiegelte eine Website wider, die zu gedeihen schien. Aber es gab eine anhaltende, nervige Inkonsistenz, die sich weigerte zu verschwinden. Die Engagement-Metriken erzählten eine völlig andere Geschichte. Absprungquoten waren astronomisch. Sitzungsdauern waren verdächtig kurz. Konversionsraten waren schrecklich im Verhältnis zum Verkehrsvolumen. Und die Bandbreitenrechnungen des Hosting-Anbieters waren atemberaubend, weit über dem, was zehn Millionen menschliche Besucher angemessen verbrauchen sollten, weil viele dieser "Besucher" Seiten mit einer Geschwindigkeit und einem Muster anforderten, das keine menschliche Browsing-Sitzung erzeugen würde.
Der Verdacht begann als stilles Bauchgefühl und wuchs sich über Monate zu einer Überzeugung aus. Etwas an dem Verkehr stimmte nicht. Die Serverprotokolle zeigten enorme Mengen von Anfragen von Benutzeragenten, die behaupteten, Googlebot, Bingbot, ChatGPTs Crawler und verschiedene andere legitime Suchmaschinen-Crawler zu sein. An der Oberfläche schien dies normal. Eine große Website zieht natürlicherweise intensive Crawler-Aktivität an. Aber das Volumen war unverhältnismäßig, und die Verhaltensmuster waren seltsam. Legitime Crawler folgen robots.txt-Direktiven, verteilen ihre Anfragen, um eine Überbelastung des Servers zu vermeiden, und stammen von bekannten IP-Bereichen, die mit ihren jeweiligen Unternehmen verbunden sind. Viel von diesem Verkehr tat nichts davon. Es bombardierte den Server unbarmherzig, ignorierte crawl-delay-Direktiven und stammte von IP-Adressen, die Cloud-Hosting-Anbietern gehörten und nicht Google oder Microsoft.
Der definitive Test war überraschend einfach. Nehmen Sie die IP-Adresse einer Anfrage, die behauptet, Googlebot zu sein, und überprüfen Sie, ob sie tatsächlich Google gehört. Echter Googlebot stammt ausschließlich von IP-Adressen innerhalb von Googles autonomem System, AS15169. Wenn eine Anfrage behauptet, Googlebot zu sein, aber von einer AWS-IP-Adresse stammt, oder eine DigitalOcean-IP-Adresse, oder eine IP außerhalb von Googles bekannten Bereichen, ist sie eindeutig gefälscht. Ein API-Aufruf zum Bot-Erkennungsdienst mit der IP-Adresse und dem User-Agent-String, und das Urteil kam sofort zurück: kein legitimer Google-Crawler. Dieser einzelne Aufruf, wiederholt über eine Verkehrsstichprobe, zeigte, dass ungefähr siebzig Prozent aller Besuche von Bots stammten, die legitime Crawler imitierten. Die zehn Millionen monatlichen Besuche waren näher an drei Millionen echten und sieben Millionen Anfragen von Eindringlingen, die Serverressourcen verbrauchten, Bandbreitenkosten aufblähten und jede Verkehrsmetrik im Prozess verunreinigten.
Der Moment, in dem die Zahlen keinen Sinn mehr ergaben
Die Erkenntnis kam nicht als plötzliche Offenbarung. Sie sammelte sich über Monate in kleinen Beobachtungen. Der erste Hinweis war die Bandbreitenrechnung. Der Hosting-Anbieter berechnete Datenübertragung, und die monatliche Rechnung stieg stetig an, obwohl der Inhalt der Website nicht proportional gewachsen war. Mehr Seiten wurden bereitgestellt, aber der Inhalt pro Seite hatte sich nicht wesentlich geändert. Die zusätzliche Bandbreite wurde von etwas verbraucht, und die Zugriffsprotokolle deuteten auf Crawler-Verkehr als primären Treiber hin. Das schien für eine Website dieser Größe angemessen zu sein, also wurde die Bedenken als Geschäftsaufwand zu den Akten gelegt.
Der zweite Hinweis war die Serverlast. Die CPU-Nutzung während der Spitzenverkehrszeiten war konsistent höher als erwartet. Die Anwendung war gut optimiert, mit Caching auf mehreren Ebenen, und die Hardwarespezifikation sollte den Verkehr bequem bewältigen. Aber die Lastdurchschnitte erzählten eine andere Geschichte. Der Server arbeitete hart, und die zusätzliche Arbeit korrelierte nicht mit benutzerseitigem Verkehrsspitzenwert, sondern mit anhaltendem, rund um die Uhr Anfordersvolumen, das niemals auf Null fiel. Echter menschlicher Verkehr folgt vorhersehbaren Mustern. Er erreicht seinen Höhepunkt während der Geschäftszeiten, fällt nachts ab und variiert je nach Wochentag. Bot-Verkehr läuft dreiundzwanzig Stunden am Tag, sieben Tage die Woche, mit konstanter Geschwindigkeit, und war in den Lastgraphen als Baseline sichtbar, die niemals unter eine bestimmte Schwelle fiel.
Der dritte Hinweis und derjenige, der die Ermittlung schließlich auslöste, war die Analyseabweichung. Google Analytics, das nur JavaScript-ausführende Besucher verfolgt, zeigte deutlich weniger Verkehr als die Serverzugriffsprotokolle. Der Unterschied zwischen den zwei Nummern war der Bot-Verkehr. Echte Browser führen JavaScript aus und registrieren sich in Analytics. Bots, die HTML-Seiten anfordern, ohne JavaScript auszuführen, erscheinen in Serverprotokollen, aber nicht in Analytics. Eine signifikante Lücke zwischen den beiden ist ein starker Indikator für intensive Bot-Aktivität, und die Lücke auf dieser Website war enorm.
Bewaffnet mit diesen Beobachtungen begann die Ermittlung ernst. Eine Stichprobe von tausend Zugriffsprotokolle, die behaupteten, von Googlebot zu sein, wurde extrahiert und ihre IP-Adressen gegen Googles veröffentlichte IP-Bereiche überprüft. Das Ergebnis war verheerend. Über siebenhundert dieser tausend Anfragen stammten von IP-Adressen, die keine Verbindung zu Google hatten. Sie stammten von AWS, Hetzner, OVH und verschiedenen anderen Hosting-Anbietern. Der User-Agent-String sagte Googlebot, aber die IP-Adresse sagte zufälliger Server in einem Rechenzentrum. Eine Erweiterung der Analyse auf Bingbot, ChatGPTs Crawler und andere behauptete Identitäten führte zu ähnlichen Ergebnissen. Der Verkehr war überwiegend gefälscht.
Wie ein API-Aufruf die Identität eines Crawlers überprüft
Der Überprüfungsprozess, der den gefälschten Verkehr offenbarte, ist konzeptionell einfach, aber praktisch mühsam, von Grund auf zu implementieren. Jede große Suchmaschine und jeder Crawler arbeitet aus einem bestimmten Satz von IP-Bereichen, die an die autonome Systemnummer ihres Unternehmens gebunden sind. Google verwendet AS15169. Microsoft verwendet mehrere ASNs für die Bing-Infrastruktur. OpenAIs Crawler verwendet seine eigenen ausgewiesenen Bereiche. Die Überprüfung eines Crawlers bedeutet, die IP-Adresse der eingehenden Anfrage zu nehmen, eine umgekehrte DNS-Suche durchzuführen, zu bestätigen, dass die Domäne dem erwarteten Muster entspricht, eine vorwärts gerichtete DNS-Suche durchzuführen, um zu bestätigen, dass die IP der Domäne entspricht, und zu überprüfen, ob die IP innerhalb der erwarteten ASN fällt. Diese mehrstufige Überprüfung erfasst ausgefeilte Fälschungen, die einen oder zwei Prüfungen bestehen können, aber die vollständige Kette nicht erfüllen.
Die Bot-Erkennungs-API kapselt diese gesamte Überprüfungskette in einem einzigen Aufruf ein. Senden Sie die IP-Adresse und den behaupteten User-Agent-String, und die API gibt ein Urteil zurück: legitim oder gefälscht, zusammen mit Beweisen, die die Bestimmung unterstützen. Die ASN der IP-Adresse, das Ergebnis der umgekehrten DNS, die erwartete ASN für die behauptete Identität und die Zuverlässigkeitsstufe der Bewertung. Für die siebzig Prozent des Verkehrs, die gefälscht waren, waren die Beweise eindeutig. Die IP-Adressen gehörten Cloud-Hosting-Anbietern, die umgekehrte DNS gab generische Hostnamen zurück, die nichts mit Google oder Microsoft zu tun hatten, und die ASN war völlig falsch für die behauptete Identität.
Was diesen Ansatz definitiv anstelle von heuristisch macht, ist, dass er sich auf überprüfbare Netzwerkinfrastruktur-Daten verlässt, nicht auf Verhaltensanalyse. Ein ausgefeilter Bot kann menschliche Browsing-Muster imitieren, seine Anfragezeitpunkte randomisieren, JavaScript ausführen und sogar CAPTCHA-Löser lösen. Aber es kann die autonome Systemnummer der IP-Adresse, von der aus es sich verbindet, nicht ändern. Wenn eine Anfrage behauptet, Googlebot zu sein, aber von einem AWS-Rechenzentrum stammt, ist sie gefälscht. Es gibt keine Grauzone, keine Wahrscheinlichkeitsscore, keine false-positive-Sorge. Die Netzwerkinfrastruktur lügt nicht, und die API legt diese Wahrheit einfach in einem Format dar, das programmgesteuert konsumiert werden kann.
Was sich änderte, nachdem falscher Verkehr identifiziert wurde
Zu wissen, dass siebzig Prozent des Verkehrs gefälscht waren, änderte sofort jede Geschäftsentscheidung, die auf Verkehrsmetriken basierte. Das tatsächliche Publikum waren drei Millionen monatliche Besucher, nicht zehn Millionen. Die echte Konversionsrate war mehr als dreimal höher als die berechnete Rate, weil der Nenner um sieben Millionen nicht existierende Benutzer aufgeblasen worden war. Die wahren Engagement-Metriken waren respektabel anstatt peinlich niedrig. Jeder Bericht, der erstellt worden war, jede Strategiesitzung, die auf Verkehrszahlen verwiesen hatte, jede Kapazitätsplanungsentscheidung, die auf Wachstumsprognosen basierte, wurde auf einem Fundament verseuchter Daten errichtet. Der falsche Verkehr hatte nicht nur Serverressourcen verbraucht. Es hatte das gesamte analytische Rahmenwerk des Unternehmens verzerrt.
Die unmittelbare technische Maßnahme war die Implementierung einer Sperrung auf Serverebene. Jede eingehende Anfrage, die behauptete, ein Suchmaschinen-Crawler zu sein, wurde in Echtzeit gegen die API überprüft. Anfragen, die die Überprüfung nicht bestanden, wurden blockiert, bevor sie die Anwendungsschicht erreichten. Der Effekt war dramatisch und unmittelbar. Der Bandbreitenverbrauch fiel stark. Die CPU-Nutzung des Servers in den Nebenstunden fiel auf einen Bruchteil des vorherigen Niveaus. Die Reaktionszeiten der Anwendung verbesserten sich, weil der Server keine Ressourcen mehr verschwendete, um Seiten für Bots zu rendern, die sie nie indexieren würden. Die Hosting-Rechnung sank proportional.
Die analytische Bereinigung dauerte länger, war aber gleichermaßen wichtig. Mit dem gefälschten Verkehr herausgefiltert wurden Analytics-Daten zum ersten Mal vertrauenswürdig. Benutzerverhaltensmuster wurden sichtbar ohne das Rauschgeflüster von Bot-Aktivität. Tatsächliche Verkehrstrends konnten identifiziert und mit Marketingmaßnahmen korreliert werden. Der Inhalt, der menschliche Besucher wirklich anzog, konnte von Inhalten unterschieden werden, die nur Bots anzogen. Diese Klarheit transformierte Entscheidungsfindung von Vermutung auf der Grundlage verseuchter Daten zu Analyse auf Basis der Realität.
Das Ausmaß des Problems im gesamten Internet
Diese Erfahrung war kein Ausreißer. Branchenschätzungen platzieren Bot-Verkehr konsistent bei dreißig bis fünfzig Prozent des gesamten Internet-Verkehrs weltweit, und für einzelne Websites kann der Anteil viel höher sein. Websites mit großer Seitenzahl, hoher Domain-Autorität oder wertvollem Inhalt ziehen Bot-Verkehr überproportional an. Scraper, gefälschte Crawler, Competitive-Intelligence-Bots, Preisüberwachungs-Bots, SEO-Analyse-Bots und verschiedene Varianten bösartiger Automatisierung tragen zum Gesamtvolumen bei. Die meisten Website-Betreiber haben keine Sichtbarkeit für diesen Verkehr, weil sie sich auf Analytics-Tools verlassen, die nur JavaScript-ausführende Besucher messen und die gesamte Bot-Schicht unsichtbar lassen.
Die finanzielle Auswirkung erstreckt sich über Bandbreitenkosten hinaus. Anzeigenplattformen berechnen auf Basis von Impressionen und Klicks. Wenn Bot-Verkehr Ad-Impressionen generiert, blasen diese Impressionen die Zahlen auf und verzerren Kampagnenleistungsmetriken. A/B-Test-Frameworks, die Bot-Besuche in ihre Stichprobe einbeziehen, führen zu unzuverlässigen Ergebnissen. Ratenlimitierungs- und Missbrauchserkennungssysteme, die gegen den Gesamtverkehr kalibriert sind, werden falsch eingestellt, wenn die Mehrheit des Verkehrs nicht menschlich ist. Selbst SEO-Strategie kann betroffen sein, da Serverprotokolle, die intensive Crawl-Aktivität zeigen, fälschlicherweise als Beweis dafür verstanden werden könnten, dass Suchmaschinen die Website tiefgreifend indexieren, während in Wirklichkeit die Crawler gefälscht sind und die echten Suchmaschinen ein viel kleineres Crawl-Budget zuweisen.
Der Bot-Erkennungsdienst entstand direkt aus dieser Erfahrung. Die Überprüfungslogik, die gebaut wurde, um den Verkehr einer Website zu bereinigen, wurde zu einer API verallgemeinert, die jede Website verwenden kann, um Crawler-Identitäten zu überprüfen. Die acht spezifischen Detektoren, die Google, Bing, OpenAI, Yandex, DuckDuckGo, Qwant und Seznam abdecken, bieten gezielte Überprüfung für die am häufigsten imitierten Crawler. Das Ergebnis ist, dass jeder Website-Betreiber die gleiche Untersuchung durchführen kann, die die Zahl von siebzig Prozent falscher Verkehr enthüllte, und die meisten werden feststellen, dass ihre eigenen Zahlen ähnlich aufgeblasen sind. Der erste Schritt zur Behebung des Problems besteht darin, zu beweisen, dass es existiert, und dieser Beweis ist nur einen API-Aufruf entfernt.
Häufig gestellte Fragen
Wie kann ich sehen, ob meine Website erheblichen falschen Bot-Verkehr hat?
Vergleichen Sie Ihre Serverzugriffsprotokolle mit Ihrer JavaScript-basierten Analyse. Eine große Lücke zwischen den zwei Nummern deutet auf erhebliche Bot-Aktivität hin. Überprüfen Sie auch die IP-Adressen von Anfragen, die behaupten, von Suchmaschinen zu stammen. Wenn viele von Cloud-Hosting-Anbietern anstelle von erwarteten Unternehmens-Netzwerken stammen, sind sie gefälscht.
Welcher Unterschied zwischen einem echten Googlebot und einem gefälschten?
Echter Googlebot stammt ausschließlich von IP-Adressen innerhalb von Googles autonomem System AS15169. Gefälschter Googlebot verwendet den gleichen User-Agent-String, verbindet sich aber von IP-Adressen von Cloud-Hosting-Anbietern wie AWS, DigitalOcean oder Hetzner. Der User-Agent-String ist trivial einfach zu fälschen, aber die IP-Adresse enthüllt den wahren Ursprung.
Wird das Blockieren von gefälschten Bots meine Suchmaschinen-Rankings beeinflussen?
Nein. Das Blockieren von gefälschten Bots betrifft nur Anfragen von IP-Adressen, die nicht der legitimen Suchmaschine gehören. Echter Googlebot, Bingbot und andere legitime Crawler greifen weiterhin normal auf die Website zu, weil sie die Überprüfung bestehen. Nur Eindringlinge werden blockiert.
Wie viel Bandbreite kann durch Blockierung von falschen Bot-Verkehr gespart werden?
Die Einsparungen hängen vom Anteil des gefälschten Verkehrs ab. Websites mit intensiver falscher Bot-Aktivität sehen üblicherweise Bandbreitenreduzierungen von vierzig bis sechzig Prozent nach Implementierung von Überprüfung und Blockierung. Für Websites mit hohen Bandbreitenkosten kann dies zu erheblichen monatlichen Einsparungen führen.
Können gefälschte Bots JavaScript ausführen und in Google Analytics erscheinen?
Einige ausgefeilte Bots führen tatsächlich JavaScript aus, was bedeutet, dass sie in Analytics-Tools erscheinen können. Die Mehrheit der gefälschten Crawler sind jedoch einfache HTTP-Anforderer-Generatoren, die kein JavaScript rendern. IP-basierte Überprüfung erfasst beide Typen, weil sie sich nicht auf Verhaltensanalyse verlässt, sondern auf den überprüfbaren Netzwerkursprung der Anfrage.
Wie behandelt die Bot-Erkennungs-API neue oder unbekannte Crawler?
Die API enthält spezifische Detektoren für die acht am häufigsten imitierten Crawler. Für unbekannte User-Agenten stellt die API ASN-Informationen und umgekehrte DNS-Daten bereit, die dem Aufrufer ermöglichen, seine eigene Bestimmung zu treffen. Das allgemeine Prinzip gilt universell: Überprüfen Sie die IP-Adresse gegen die bekannte Infrastruktur der behaupteten Identität.