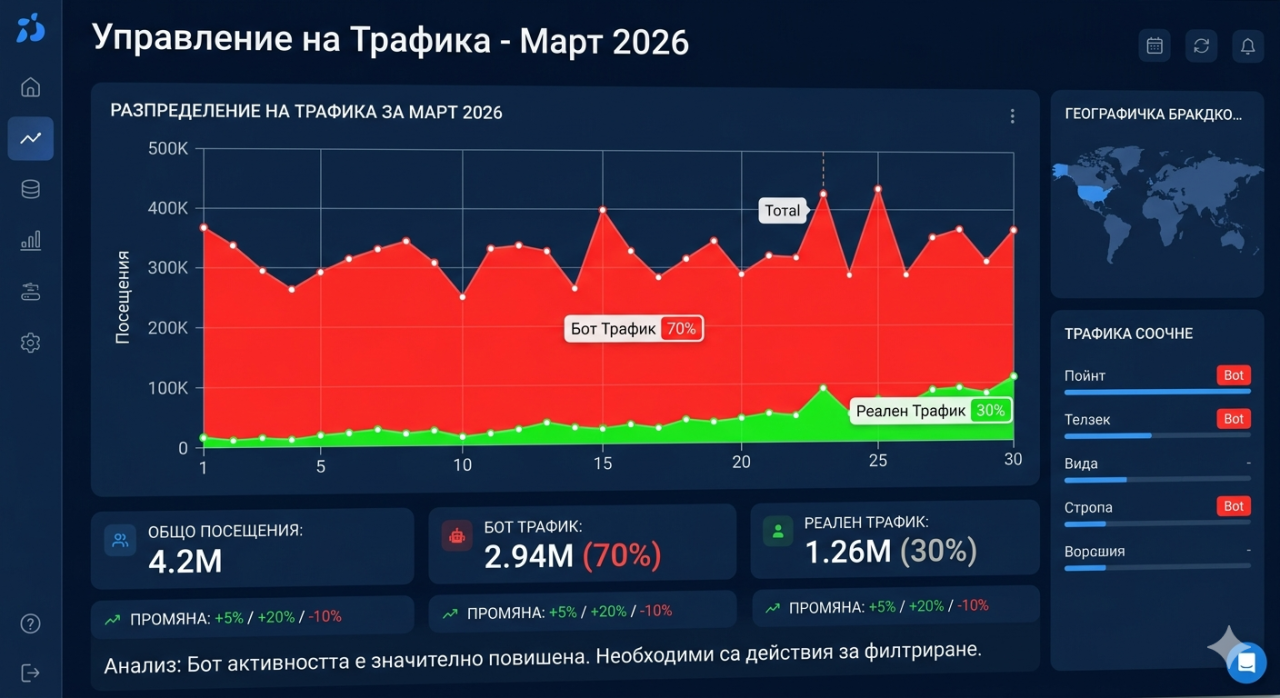
Syv procent af min trafik var falsk, og her er hvordan jeg beviste det med et enkelt API-kald
Analyticdashboardet viste ti millioner månedlige besøg. Ti millioner. Dette tal burde have været en grund til fejring, og det var det i en periode. Trafikgraferne pegede opad, sidevisningsantal blev samlet imponerende, og båndbreddeforbruget afspejlede et websted, der syntes at trives. Men der var en vedvarende, irriterende inkonsistens, der nægtede at forsvinde. Engagement-metrikerne fortalte en helt anderledes historie. Springfrekvenserne var astronomiske. Sessionvarigheder var mistænkeligt korte. Konverteringsfrekvenser var dårlige i forhold til trafikvolumen. Og båndbredderegninger fra værtsudbyderen var forbløffende, langt overstiggende hvad ti millioner menneskelige besøgende skulle være rimelige med at forbruge, fordi mange af disse "besøgende" anmodede sider med en hastighed og mønster, som ingen menneskelig browsersession ville producere.
Mistanken startede som en stille fornemmelse og voksede til en overbevisning over måneder. Noget ved trafikken var galt. Serverlogge viste enorme mængder anmodninger fra brugeragenter, der udgav sig for at være Googlebot, Bingbot, ChatGPT's crawler og forskellige andre legitime søgemaskine-crawlere. På overfladen virkede dette normalt. Et stort websted tiltrækker naturligvis tung crawler-aktivitet. Men volumen var uforholdsmæssig, og adfærdsmønstrene var mærkelige. Legitime crawlere følger robots.txt-direktiver, afstander deres anmodninger for at undgå at overvælde serveren og kommer fra kendte IP-intervaller, der er knyttet til deres respektive virksomheder. Meget af denne trafik gjorde ingen af disse ting. Det bombede serveren ubarmhjertiggt, ignorerede crawl-delay-direktiver og stammede fra IP-adresser, der tilhørte cloud-hostingudbydere snarere end Google eller Microsoft.
Den definitive test var overraskende enkel. Tag IP-adressen på en anmodning, der hævder at være Googlebot, og kontroller, om den faktisk tilhører Google. Ægte Googlebot stammer udelukkende fra IP-adresser inden for Googles autonome system, AS15169. Hvis en anmodning hævder at være Googlebot, men kommer fra en AWS IP-adresse, eller en DigitalOcean IP-adresse, eller en IP uden for Googles kendte områder, er det utvetydigt falsk. Et API-kald til bot-detektionstjenesten med IP-adressen og brugeragentstreng, og dommen kom tilbage øjeblikkeligt: ikke en legitim Google-crawler. Det eneste kald, gentaget på tværs af et trafikeksempel, afslørede, at cirka syv procent af alle besøg var fra bots, der udgav sig for legitime crawlere. De ti millioner månedlige besøg var tættere på tre millioner ægte, og syv millioner anmodninger fra indtrængere, der forbrugte serverressourcer, oppustede båndbreddeomkostninger og forurenegerede hver trafikmetrik i processen.
Øjeblikket hvor tallene holdt op med at give mening
Realiseringen ankom ikke som en pludselig åbenbaring. Det akkumulerede gennem små observationer over måneder. Den første vigtig var båndbredderegningen. Værtsudbyderen opkrævede for dataoverførsel, og den månedlige regning steg stedse, selvom indholdet på webstedet ikke var vokset proportionalt. Flere sider blev serveret, men indholdet pr. side havde ikke ændret sig væsentligt. Den yderligere båndbredde blev forbrugt af noget, og adgangsloggene pegede på crawler-trafik som den primære chauffør. Det virkede rimeligt for et websted af denne størrelse, så bekymringen blev arkiveret som en omkostning ved at drive virksomhed.
Den anden vigtig var serverbelastningen. CPU-forbrug under timer med spidstrafik var konsekvent højere end forventet. Applikationen var veloptimeret, med caching på flere niveauer, og hardwarespecifikationen skulle have håndteret trafikken komfortabelt. Men belastningsgennemsnit fortalte en anden historie. Serveren arbejdede hårdt, og det ekstra arbejde korrelerede ikke med brugerorienterede trafiktoppe, men med vedvarende, rundt-omkring-uret anmodningsvolumen, der aldrig dykkede til nul. Reel menneskelig trafik følger forudsigelige mønstre. Det topper i erhvervstid, falder om natten og varierer efter ugedag. Bot-trafik kører tre og tyve timer i døgnet, syv dage i ugen, med en konstant hastighed, og det var synligt i belastningsgraferne som en baseline, der aldrig gik under en vis tærskel.
Den tredje vigtig, og den der til sidst udløste undersøgelsen, var analytisk-uoverensstemmelsen. Google Analytics, som kun sporer JavaScript-udførende besøgende, viste væsentligt mindre trafik end serveradgangsloggene. Forskellen mellem de to tal var bot-trafikken. Ægte browsere udfører JavaScript og registrerer sig i analyser. Bots, der anmoder om HTML-sider uden at udføre JavaScript, vises i serverloggene, men ikke i analyser. En betydelig forskel mellem de to er en stærk indikator for tung bot-aktivitet, og hullet på dette websted var enormt.
Bevæbnet med disse observationer begyndte undersøgelsen for alvor. En prøve på tusind adgangslog-poster, der hævdede at være fra Googlebot, blev ekstraheret, og deres IP-adresser blev kontrolleret mod Googles offentliggjorte IP-intervaller. Resultatet var ødelæggende. Over syv hundrede af disse tusind anmodninger kom fra IP-adresser, der slet ikke havde nogen forbindelse til Google. De stammede fra AWS, Hetzner, OVH og forskellige andre hostingudbydere. Brugeragentstreng sagde Googlebot, men IP-adressen sagde tilfældig server i et datacenter. Udvidelse af analysen til Bingbot, ChatGPT's crawler og andre påstået identiteter producerede lignende resultater. Trafikken var overvejende falsk.
Hvordan et API-kald verificerer enhver crawlers identitet
Verifikationsprocessen, der afslørede den falske trafik, er begrebsmæssigt enkel, men praktisk møjsommelig at implementere fra grunden. Hver større søgemaskine og crawler fungerer fra et specifikt sæt IP-intervaller, der er knyttet til deres virksomheds autonome systemnummer. Google bruger AS15169. Microsoft bruger flere ASN'er for Bings infrastruktur. OpenAI's crawler bruger sine egne udpegede områder. Verifikation af en crawler betyder at tage IP-adressen på den indgående anmodning, udføre et omvendt DNS-opslag, bekræfte domænet matcher det forventede mønster, udføre et fremad DNS-opslag for at bekræfte IP'en matcher domænet og kontrollere, om IP'en falder inden for den forventede ASN. Denne multi-trin-verifikation fanger sofistikerede falsknerier, der kan passere en eller to kontroller, men svigte i den komplette kæde.
Bot-detektion-API'et indkapsler hele verifikationskæden i et enkelt kald. Send IP-adressen og den påståede brugeragentstreng, og API'et returnerer en kendelse: legitim eller falsk, sammen med bevis, der understøtter bestemmelsen. ASN for IP-adressen, det omvendte DNS-resultat, den forventede ASN for den påståede identitet og tillidsgraden for vurderingen. For de syv procent af trafikken, der var falsk, var beviserne utvetydige. IP-adresserne tilhørte cloud-hostingudbydere, det omvendte DNS returnerede generiske værtsnavne, der ikke havde noget at gøre med Google eller Microsoft, og ASN var helt forkert for den påståede identitet.
Hvad der gør denne tilgang definitiv snarere end heuristisk er, at den er afhængig af verificerbar netværksinfrastrukturdata, ikke adfærdsanalyse. En sofistikeret bot kan efterligne menneskelige browseringmønstre, tilfældiggøre dets anmodningstidspunkt, udføre JavaScript og endda løse CAPTCHA'er. Men det kan ikke ændre det autonome systemnummer for IP-adressen, det opretter forbindelse fra. Hvis en anmodning hævder at være Googlebot, men stammer fra et AWS-datacenter, er det falsk. Der er ingen gråzone, ingen sandsynlighedsscore, ingen falsk positiv bekymring. Netværksinfrastrukturen lyver ikke, og API'et blotter simpelthen denne sandhed i et format, der kan forbruges programmatisk.
Hvad ændrede sig efter falsk trafik blev identificeret
At vide, at syv procent af trafikken var falsk ændrede straks hver forretningsbeslutning, der var baseret på trafikmetrikker. Det rigtige publikum var tre millioner månedlige besøgende, ikke ti millioner. Den rigtige konverteringsfrekvens var mere end tre gange højere end den beregnede sats, fordi nævneren var oppustet af syv millioner ikke-eksistente brugere. De sande engagement-metrikker var respektable snarere end skammeligt lave. Hver rapport, der var blevet genereret, hver strategimøde, der havde refereret til trafiktal, hver kapacitetsplanlægningsbeslutning, der var baseret på vækstprojektioner, var bygget på et grundlag af forurenet data. Den falske trafik havde ikke bare forbrugt serverressourcer. Det havde fordrejet hele det analytiske rammev for virksomheden.
Den umiddelbare tekniske handling var at implementere blokering på serverniveau. Hver indgående anmodning, der hævdede at være en søgemaskine-crawler, blev verificeret mod API'et i realtid. Anmodninger, der ikke bestod verifikation, blev blokeret, før de nåede applikationslaget. Effekten var dramatisk og øjeblikkelig. Båndbreddeforbrugelse faldt kraftigt. Server-CPU-forbrug i løbet af mimohorar faldt til en brøkdel af dets tidligere niveau. Applikationssvarstiderne blev forbedret, fordi serveren ikke længere sløsede ressourcer på at gengive sider til bots, der aldrig ville indeksere dem. Värtregningen faldt proportionalt.
Den analytiske rengøring tog længere, men var lige så vigtig. Med den falske trafik filtreret ud blev analysedata pålidelig for første gang. Brugeradfærdsmønstre blev synlige uden støjgulvet for bot-aktivitet. Faktisk trafiktrends kunne identificeres og korreleres med markedsføringsindsats. Det indhold, der faktisk tiltrækked menneskelige besøgende, kunne skelnes fra det indhold, der kun tiltrækked bots. Denne klarhed transformerede beslutningstagning fra gætværk baseret på forurenet data til analyse baseret på virkelighed.
Problemets omfang på tværs af internettet
Denne erfaring var ikke en aflejer. Industriestimat placerer konsekvent bot-trafik ved tredive til halvtreds procent af al internetodie globalt, og for individuelle websteder kan andelen være meget højere. Websteder med stort sidenummer, høj domæneautoritet eller værdifuldt indhold tiltrækker bot-trafik uforholdsmæssigt. Skrabere, falske crawlere, bots til konkurrentintelligens, prisovervågning, SEO-analysebots og forskellige varianter af ondsindet automatisering bidrager til det samlede. De fleste websted-operatører har ingen synlighed til denne trafik, fordi de er afhængige af analyseværktøjer, der kun måler JavaScript-udførende besøgende, hvilket lader hele bot-laget usynlig.
Den økonomiske indvirkning strækker sig uden for båndbreddeomkostninger. Annonceplatforme opkræver baseret på visninger og klik. Hvis bot-trafik genererer ad-visninger, oppuster disse visninger tallene og fordrejer kampagnens ydeelsesmetrikker. A/B-test-rammer, der inkluderer bot-besøg i deres eksempel, producerer upålidelige resultater. Satssbegrænsning og misbrug-detektion systemer kalibreret mod samlet trafik vil være forkert stemt, hvis flertallet af den trafik ikke er menneskelig. Selv SEO-strategi kan påvirkes, da serverloggene, der viser tung crawl-aktivitet, kan blive fejlanset som bevis for, at søgemaskiner dybt indekserer webstedet, når crawlere i virkeligheden er falske, og de rigtige søgemaskiner fordeler meget mindre crawl budget.
Bot-detektionstjenesten blev født direkte fra denne erfaring. Verifikationslogikken, der blev bygget for at rense ét websteds trafik, blev generaliseret til et API, som ethvert websted kan bruge til at verificere crawler-identiteter. De otte specifikke detektor er der dækker Google, Bing, OpenAI, Yandex, DuckDuckGo, Qwant og Seznam give målrettet verifikation for de mest almindeligt gendigede crawlere. Resultatet er, at enhver websted-operator kan køre den samme undersøgelse, der afslørede tallet for syv procent falsk trafik, og de fleste vil opdage, at deres egne tal er tilsvarende oppustet. Det første skridt mod at løse problemet er at bevise, at det eksisterer, og det bevis er ét API-kald væk.
Ofte stillede spørgsmål
Hvordan kan jeg se, om mit websted har betydelig falsk bot-trafik?
Sammenlign dine serveradgangsloggerne med dine JavaScript-baserede analyser. Et stort hul mellem de to tal indikerer betydelig bot-aktivitet. Derudover skal du kontrollere IP-adresserne for anmodninger, der hævder at være fra søgemaskiner. Hvis mange kommer fra cloud-hostingudbydere snarere end forventede virksomhedsnetværk, er de falske.
Hvad er forskellen mellem en rigtig Googlebot og en falsk?
Ægte Googlebot stammer udelukkende fra IP-adresser inden for Googles autonome system AS15169. Falsk Googlebot bruger samme brugeragentstreng, men opretter forbindelse fra IP-adresser, der tilhører cloud-hostingudbydere som AWS, DigitalOcean eller Hetzner. Brugeragentstreng er trivielt let at forfalske, men IP-adressen afslører det sande ophav.
Vil blokering af falske bots påvirke min søgemaskineplacering?
Nej. Blokering af falske bots påvirker kun anmodninger fra IP-adresser, der ikke tilhører den legitime søgemaskine. Ægte Googlebot, Bingbot og andre legitime crawlere vil fortsætte med at få adgang til webstedet normalt, fordi de består verifikationstjek. Kun indtrængere blokeres.
Hvor meget båndbredde kan spares ved at blokere falsk bot-trafik?
Besparelsen afhænger af andelen af falsk trafik. Websteder med tung falsk bot-aktivitet ser ofte båndbredde-reduktioner på fyrre til tres procent efter implementering af verifikation og blokering. For websteder med høje båndbreddeomkostninger kan dette oversættes til betydelige månedlige besparelser.
Kan falske bots udføre JavaScript og vises i Google Analytics?
Nogle sofistikerede bots udfører faktisk JavaScript, hvilket betyder, at de kan vises i analyseværktøjer. Imidlertid er størstedelen af falske crawlere simple HTTP-anmodningsgeneratorer, der ikke gengiver JavaScript. IP-baseret verifikation fanger begge typer, fordi den ikke er afhængig af adfærdsanalyse, men af den verificerbare netværksoprindelse af anmodningen.
Hvordan håndterer bot-detektion-API'et nye eller ukendte crawlere?
API'et inkluderer specifikke detektorer til de otte mest almindeligt gendigede crawlere. For ukendte brugeragenter giver API'et ASN-information og omvendt DNS-data, der gør det muligt for opkaldsgiveren at foretage sin egen bestemmelse. Det generelle princip gælder universelt: verificer IP-adressen mod den påståede identitets kendte infrastruktur.