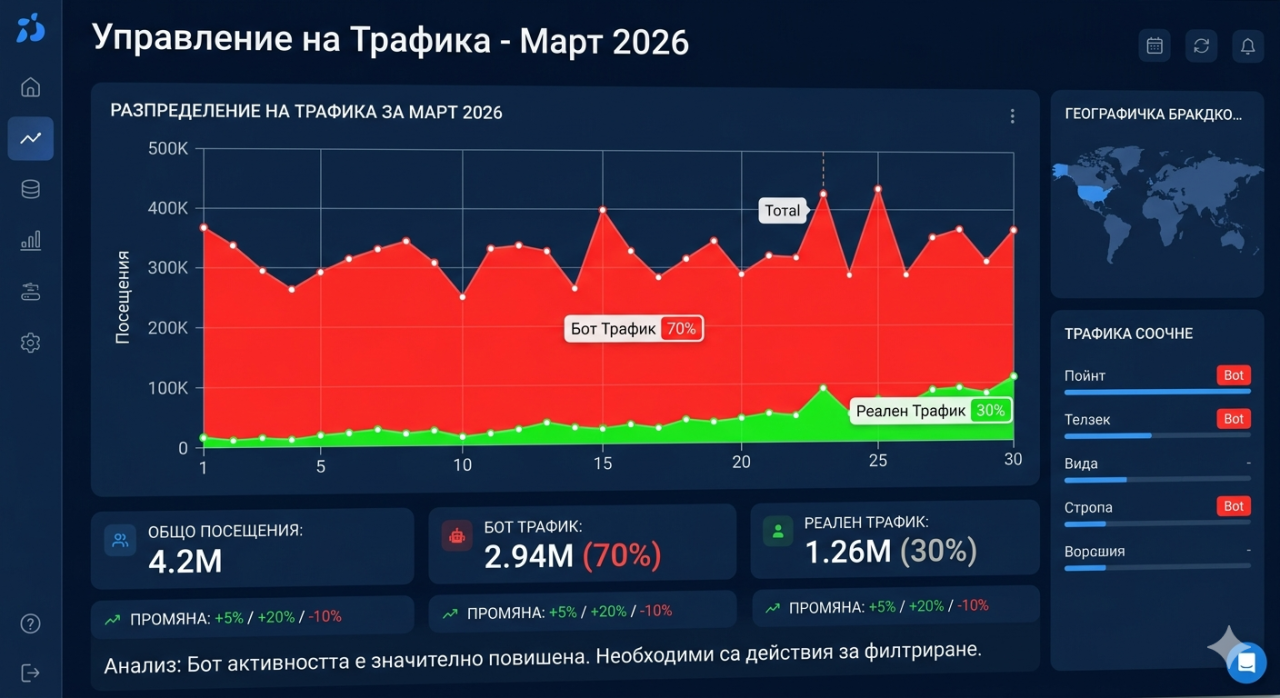
Zeventig procent van mijn traffic was nep en hier is hoe ik het met één API-aanroep heb bewezen
Het analyticsdashboard toonde tien miljoen maandelijkse bezoeken. Tien miljoen. Dat getal had aanleiding moeten zijn voor viering, en voor een tijd was het ook zo. De verkeersgrafieken wezen omhoog, de paginaweergavetellingen stapelden indrukwekkend op, en het bandbreedtegebruik weerspiegelde een site die leek te gedijen. Maar er was een hardnekkige, gnaggende inconsistentie die weigerde weg te gaan. De betrokkenheidsmaten vertelden een heel ander verhaal. De stuiterpercentages waren astronomisch hoog. De sessieduren waren verdacht kort. De conversieratio's waren abominabel ten opzichte van het verkeersvolume. En de bandbreedterekenin
gen van de hostingprovider waren verschrikkelijk, veel hoger dan wat tien miljoen menselijke bezoekers redelijk zouden moeten verbruiken, omdat veel van deze "bezoekers" pagina's aanvroegen in een tempo en patroon dat geen menselijke browsersessie zou produceren.
Het vermoeden begon als een stille intuïtie en groeide over maanden uit tot een overtuiging. Er klopt iets niet aan het verkeer. De serverlogboeken toonden enorme volumes verzoeken van user agents die beweerden Googlebot, Bingbot, de crawler van ChatGPT en verschillende andere legitieme zoekmachinecrawlers te zijn. Aan de oppervlakte leek dit normaal. Een grote site trekt natuurlijk veel crawleractività aan. Maar het volume was onevenredig, en de gedragspatronen waren vreemd. Legitieme crawlers volgen robots.txt-richtlijnen, spreiden hun verzoeken uit om de server niet te overbelasten, en komen van bekende IP-bereiken die aan hun respectieve bedrijven zijn gekoppeld. Veel van dit verkeer deed geen van die dingen. Het bombardeerde de server onverbiddelijk, negeerde crawl-delay-richtlijnen en kwam van IP-adressen die aan cloudhostingproviders toebehoorden in plaats van aan Google of Microsoft.
De sluitende test was verrassend eenvoudig. Neem het IP-adres van een verzoek dat beweert Googlebot te zijn en controleer of het werkelijk bij Google hoort. Real Googlebot komt uitsluitend van IP-adressen binnen Googles autonoom systeemnummer AS15169. Als een verzoek beweert Googlebot te zijn maar afkomstig is van een AWS IP-adres, een DigitalOcean IP-adres of enig IP-adres buiten Googles bekende bereiken, is het onmiskenbaar nep. Eén API-aanroep naar de botdetectieservice met het IP-adres en user agent string, en het oordeel kwam onmiddellijk terug: geen legitieme Google-crawler. Die enkele aanroep, herhaald over een steekproef van het verkeer, onthulde dat ongeveer zeventig procent van alle bezoeken afkomstig was van bots die legitieme crawlers nadeden. De tien miljoen maandelijkse bezoeken waren dichter bij drie miljoen echte, en zeven miljoen verzoeken van impostors die serverresources verbruikten, bandbreedtekosten opbliezen, en elke analyticsmeting vervuilden.
Het moment waarop de getallen geen zin meer maakten
De realisatie kwam niet als een plotselinge openbaring. Het stapelde zich op door kleine waarnemingen over maanden. De eerste aanwijzing was de bandbreedterekening. De hostingprovider berekende voor gegevensoverdracht, en de maandelijkse rekening steeg gestaag ondanks dat de inhoud op de site niet evenredig was gegroeid. Meer pagina's werden bediend, maar de inhoud per pagina was niet significant veranderd. De extra bandbreedteverbruik werd veroorzaakt door iets, en de toegangslogboeken wezen op crawlerverkeer als de primaire drijver. Dat leek redelijk voor een site van die grootte, dus het bezorgdheid werd opgeslagen als een bedrijfskosten.
De tweede aanwijzing was de serverbelasting. Het CPU-gebruik tijdens piekverkeersuren was consistent hoger dan verwacht. De applicatie was goed geoptimaliseerd, met caching op meerdere lagen, en de hardwarespecificatie zou het verkeer comfortabel moeten hebben afgehandeld. Maar de belastingsgemiddelden vertelden een ander verhaal. De server werkte hard, en het extra werk correleerde niet met gebruikers-facing verkeerspieken maar met aanhoudend, rond-de-klok verzoekvolume dat nooit naar nul daalde. Real menselijk verkeer volgt voorspelbare patronen. Het piekt tijdens bedrijfsuren, daalt 's nachts, en varieert per dag van de week. Botverkeer draait vierentwintig uur per dag, zeven dagen per week, met een constant tempo, en het was zichtbaar in de belastingsgrafieken als een basislijn die nooit onder een bepaalde drempel daalde.
De derde aanwijzing, en degene die uiteindelijk het onderzoek triggerde, was de analyticsdiscrepantie. Google Analytics, dat alleen JavaScript-uitvoerende bezoekers bijhoudt, toonde aanzienlijk minder verkeer dan de serverlogboeken. Het verschil tussen de twee getallen was het botverkeer. Echte browsers voeren JavaScript uit en registreren zich in analytics. Bots die HTML-pagina's aanvragen zonder JavaScript uit te voeren, verschijnen in serverlogboeken maar niet in analytics. Een significant gat tussen de twee is een sterke indicator van zware botactiviteit, en het gat op deze site was enorm.
Gewapend met deze waarnemingen begon het onderzoek in volle ernst. Een steekproef van duizend toegangslogposten die beweerden van Googlebot afkomstig te zijn, werden geëxtraheerd en hun IP-adressen gecontroleerd tegen Googles gepubliceerde IP-bereiken. Het resultaat was vernietigend. Meer dan zevenhonderd van die duizend verzoeken kwamen van IP-adressen die helemaal geen associatie met Google hadden. Ze waren afkomstig van AWS, Hetzner, OVH en verschillende andere hostingproviders. De user agent string zei Googlebot, maar het IP-adres zei willekeurige server in een datacentrum. Uitbreiding van de analyse naar Bingbot, ChatGPT's crawler, en andere geclaimde identiteiten produceerde soortgelijke resultaten. Het verkeer was overweldigend nep.
Hoe één API-aanroep de identiteit van elke crawler verifieert
Het verificatieproces dat het nep verkeer onthulde is conceptueel eenvoudig maar praktisch moeizaam om van nul af aan te implementeren. Elke grote zoekmachine en crawler werkt vanuit een specifieke reeks IP-bereiken gebonden aan het autonoom systeemnummer van hun bedrijf. Google gebruikt AS15169. Microsoft gebruikt verschillende ASN's voor de infrastructuur van Bing. De crawler van OpenAI gebruikt zijn eigen aangewezen bereiken. Een crawler verifiëren betekent het IP-adres van het inkomende verzoek nemen, een reverse DNS-lookup uitvoeren, het domein bevestigen overeenkomt met het verwachte patroon, een forward DNS-lookup uitvoeren om te bevestigen dat het IP met het domein overeenkomt, en controleren of het IP binnen het verwachte ASN valt. Deze multi-stap verificatie vangt geavanceerde vervalsingen die één of twee controles kunnen doorstaan maar de volledige keten niet.
De botdetectie-API omhult deze volledige verificatieketen in één aanroep. Stuur het IP-adres en de geclaimde user agent string, en de API retourneert een oordeel: legitiem of nep, samen met het bewijs dat de bepaling ondersteunt. Het ASN van het IP-adres, het reverse DNS-resultaat, het verwachte ASN voor de geclaimde identiteit, en het vertrouwensniveau van de beoordeling. Voor het zeventig procent van het verkeer dat nep was, was het bewijs ondubbelzinnig. De IP-adressen behoorden aan cloudhostingproviders, de reverse DNS gaf generieke hostnamen terug die niets met Google of Microsoft te maken hadden, en het ASN was volkomen verkeerd voor de geclaimde identiteit.
Wat deze benadering definitief maakt in plaats van heuristisch is dat het vertrouwt op verifieerbare netwerkinfrastructuurgegevens, geen gedragsanalyse. Een geavanceerde bot kan menselijke browserpatronen nabootsen, verzoektiming willekeurig maken, JavaScript uitvoeren, en zelfs CAPTCHA's oplossen. Maar het kan het autonoom systeemnummer van het IP-adres waar het verbinding mee maakt niet veranderen. Als een verzoek beweert Googlebot te zijn maar afkomstig is van een AWS-datacentrum, is het nep. Er is geen grijze zone, geen waarschijnlijkheidsscore, geen bezorgdheid over vals positieve. De netwerkinfrastructuur liegt niet, en de API bloot die waarheid eenvoudig in een formaat dat programmatisch kan worden verbruikt.
Wat veranderde nadat het nep verkeer werd geïdentificeerd
Wetend dat zeventig procent van het verkeer nep was, veranderde onmiddellijk elke zakelijke beslissing die op verkeersmetrieken was gebaseerd. Het werkelijke publiek was drie miljoen maandelijkse bezoekers, niet tien miljoen. De echte conversieratio was meer dan drie keer hoger dan de berekende ratio, omdat de noemer was opgeblazen door zeven miljoen niet-bestaande gebruikers. De echte betrokkenheidsmaten waren respectabel in plaats van beschamend laag. Elk rapport dat was gegenereerd, elke strategieverga
dering die naar verkeersgetallen verwees, elke capaciteitsplanningsbeslissing die op groeiprojecties was gebaseerd, was gebouwd op een fundament van vervuilde gegevens. Het nep verkeer had niet alleen serverresources verbruikt. Het had het hele analytische kader van het bedrijf vervormd.
De onmiddellijke technische actie was het implementeren van blokkering op serverniveau. Elk inkomend verzoek dat beweerde een zoekmachinecrawler te zijn, werd in real-time tegen de API geverifieerd. Verzoeken die verificatie niet doorstonden, werden geblokkeerd voordat ze de applicatielaag bereikten. Het effect was dramatisch en onmiddellijk. Bandbreedteverbruik daalde scherp. Het CPU-gebruik van de server tijdens daluren viel tot een fractie van het vorige niveau. De responstijden van de applicatie verbeterden omdat de server geen meer resources verspilde aan het renderen van pagina's voor bots die deze nooit zouden indexeren. De hostingrekening daalde evenredig.
De analytische opschoning duurde langer maar was even belangrijk. Met het nep verkeer gefilterd, werden de analyticgegevens voor het eerst betrouwbaar. Gebruikergedragspatronen werden zichtbaar zonder de ruisvloer van botactiviteit. Werkelijke verkeerstendenzen konden worden geïdentificeerd en gecorreleerd met marketinginspanningen. De inhoud die werkelijk menselijke bezoekers aantrok, kon worden onderscheiden van de inhoud die alleen bots aantrok. Deze duidelijkheid transformeerde de besluitvorming van giswerk gebaseerd op vervuilde gegevens naar analyse gebaseerd op realiteit.
De schaal van het probleem over het internet
Deze ervaring was geen uitbijter. Branche-schattingen plaatsen botverkeer consistent op dertig tot vijftig procent van het gehele internetverkeer wereldwijd, en voor individuele sites kan het percentage veel hoger zijn. Sites met grote paginatellingen, hoge domeinautoriteit of waardevolle inhoud trekken botverkeer onevenredig aan. Scrapers, valse crawlers, concurrentieanalysebots, prijsmonitoringbots, SEO-analysebots, en verschillende soorten kwaadaardige automatisering dragen allemaal bij aan het totaal. De meeste site-operators hebben geen zicht op dit verkeer omdat ze vertrouwen op analysetools die alleen JavaScript-uitvoerende bezoekers meten, waardoor de gehele botlaag onzichtbaar is.
De financiële impact reikt verder dan bandbreedtekosten. Advertentieplatformen berekenen op basis van indrukken en klikken. Als botverkeer advertentie-indrukken genereert, blazen die indrukken de getallen op en vervormen ze metriek van campagneprestaties. A/B-testframework's die botbezoeken in hun steekproef opnemen, produceren onbetrouwbare resultaten. Rate limiting en detectiesystemen voor misbruik gekalibreerd tegen totaalverkeer zullen onjuist worden afgestemd als het merendeel van dat verkeer niet menselijk is. Zelfs SEO-strategie kan worden beïnvloed, omdat serverlogboeken met zware crawlactiviteit kunnen worden verkeerd uitgelegd als bewijs dat zoekmachines de site diep indexeren, terwijl in werkelijkheid de crawlers vervalsing zijn en de echte zoekmachines een veel kleinere crawlbudget toewijzen.
De botdetectieservice werd direct uit deze ervaring geboren. De verificatielogica die werd gebouwd om het verkeer van één site op te schonen, werd gegeneraliseerd in een API die elke site kan gebruiken om crawleridentiteiten te verifiëren. De acht specifieke detectors die Google, Bing, OpenAI, Yandex, DuckDuckGo, Qwant en Seznam bestrijken, bieden gerichte verificatie voor de meest nagebootste crawlers. Het resultaat is dat elke site-operator hetzelfde onderzoek kan uitvoeren dat het zeventig procent nep verkeerspercentage onthulde, en de meesten zullen ontdekken dat hun eigen getallen soortgelijk zijn opgeblazen. De eerste stap naar het oplossen van het probleem is bewijzen dat het bestaat, en dat bewijs is één API-aanroep verwijderd.
Frequently Asked Questions
Hoe kan ik zien of mijn site aanzienlijk nep botverkeer heeft?
Vergelijk uw serverlogboeken tegen uw JavaScript-gebaseerde analyticgegevens. Een groot gat tussen de twee getallen duidt op aanzienlijke botactiviteit. Controleer bovendien de IP-adressen van verzoeken die beweren van zoekmachines afkomstig te zijn. Als veel van cloudhostingproviders in plaats van de verwachte bedrijfsnetwerken afkomstig zijn, zijn ze nep.
Wat is het verschil tussen een echte Googlebot en een nep?
Echte Googlebot komt uitsluitend van IP-adressen binnen Googles autonoom systeemnummer AS15169. Valse Googlebot gebruikt dezelfde user agent string maar verbindt van IP-adressen die behoren tot cloudhostingproviders zoals AWS, DigitalOcean of Hetzner. De user agent string is triviaal gemakkelijk om te vervalsen, maar het IP-adres onthult de ware oorsprong.
Zal het blokkeren van nep bots mijn zoekmachinepositie beïnvloeden?
Nee. Het blokkeren van nep bots beïnvloedt alleen verzoeken van IP-adressen die niet tot de legitieme zoekmachine behoren. Echte Googlebot, Bingbot en andere legitieme crawlers hebben normale toegang tot de site omdat ze de verificatie doorstaan. Alleen impostors worden geblokkeerd.
Hoeveel bandbreedteverbruik kan worden bespaard door nep botverkeer te blokkeren?
De besparing hangt af van het aandeel nep verkeer. Sites met zware nep botactiviteit zien gewoonlijk bandbreedteverminderingen van veertig tot zestig procent na implementatie van verificatie en blokkering. Voor sites met hoge bandbreedtekosten kan dit zich vertalen in aanzienlijke maandelijkse besparingen.
Kunnen nep bots JavaScript uitvoeren en verschijnen in Google Analytics?
Enkele geavanceerde bots voeren inderdaad JavaScript uit, wat betekent dat ze in analysetools kunnen verschijnen. Het merendeel van de nep crawlers zijn echter eenvoudige HTTP-verzoekgenerators die JavaScript niet renderen. IP-gebaseerde verificatie vangt beide typen omdat het niet op gedragsanalyse vertrouwt maar op de verifieerbare netwerkoorsprong van het verzoek.
Hoe gaat de botdetectie-API om met nieuwe of onbekende crawlers?
De API bevat specifieke detectors voor de acht meest nagebootste crawlers. Voor onbekende user agents biedt de API ASN-informatie en reverse DNS-gegevens die de beller in staat stellen hun eigen bepaling te maken. Het algemene principe is universeel van toepassing: verifieer het IP-adres tegen de bekende infrastructuur van de geclaimde identiteit.