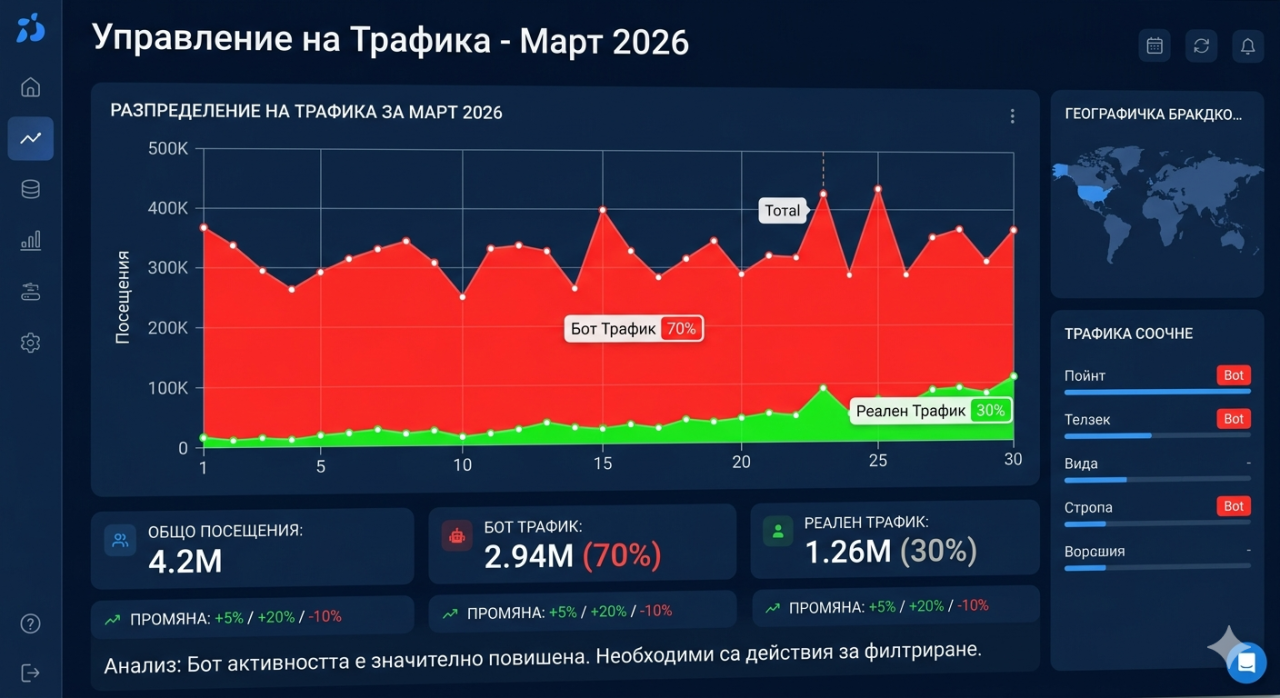
Sedmdesát procent mého provozu bylo falešné a zde je návod, jak jsem to prokázal jediným voláním API
Analytický panel ukazoval deset milionů měsíčních návštěv. Deset milionů. Toto číslo by mělo být důvodem k radosti, a po dobu byla. Grafy provozu směřovaly vzhůru, počty zobrazení stránky se hromadily působivě a spotřeba šířky pásma odrážela web, který se zdál být prosperující. Ale existovala trvalá, znervózňující nekonzistence, která odmítala zmizet. Metriky zapojení vyprávěly úplně jiný příběh. Míry odskoků byly astronomické. Doba trvání relace byla podezřele krátká. Míry konverzí byly příšerné vzhledem k objemu provozu. A vyúčtování šířky pásma od poskytovatele hostingu bylo ohromující, daleko překračující to, co by mělo deset milionů lidských návštěvníků přiměřeně spotřebovat, protože mnozí z těchto "návštěvníků" si vyžádali stránky tempem a vzorem, který by neprovedl žádný lidský relací procházení.
Podezření začalo jako tiché tušení a v průběhu měsíců se přeměnilo v přesvědčení. Něco s provozem nebylo v pořádku. Protokoly serveru ukazovaly obrovské objemy požadavků od uživatelských agentů tvrdících, že jsou Googlebot, Bingbot, crawler ChatGPT a různých dalších legitimních vyhledávacích crawlerů. Na první pohled se to zdálo normální. Velký web přirozeně přitahuje těžkou aktivitu crawleru. Ale objem byl neúměrný a vzory chování byly podivné. Legitimní crawlery dodržují pokyny robots.txt, rozesílají své požadavky, aby se vyhnuly přetížení serveru, a pocházejí ze známých rozsahů IP adres spojených s jejich příslušnými společnostmi. Velká část tohoto provozu to nedělala. Bezúměrně zatěžoval server, ignoroval pokyny crawl-delay a pocházel z IP adres, které patřily poskytovatelům cloudového hostingu spíše než Google nebo Microsoft.
Definitivní test byl překvapivě jednoduchý. Vezměte si IP adresu požadavku, který tvrdí, že je Googlebot, a zkontrolujte, zda skutečně patří Googlu. Skutečný Googlebot pochází výhradně z IP adres v rámci autonomního systému společnosti Google, AS15169. Pokud požadavek tvrdí, že je Googlebot, ale pochází z IP adresy AWS, nebo IP adresy DigitalOcean, nebo jakékoli IP mimo známé rozsahy Googlu, je to jednoznačně falešné. Jedno volání API do služby detekce botů s IP adresou a řetězcem uživatelského agenta a rozsudek přišel okamžitě: ne legitimní vyhledávač Google. Toto jediné volání, opakované na vzorku provozu, odhalilo, že přibližně sedmdesát procent všech návštěv pocházelo od botů vydávajících se za legitimní crawlery. Deset milionů měsíčních návštěv bylo blíže třem milionům skutečných a sedmi milionům požadavků od vetřelců, kteří konzumovali prostředky serveru, nafukovali náklady na šířku pásma a znečišťovali každou metriku analýz v procesu.
Moment, kdy čísla přestala dávat smysl
Realizace nepřišla jako náhlé zjevení. V průběhu měsíců se hromadila malými pozorováními. První stopa byla účet za šířku pásma. Poskytovatel hostingu účtoval za přenos dat a měsíční účet stále rostl, i když se obsah na webu nezvětšil proporcionálně. Byly doručovány více stránky, ale obsah na stránku se nezměnil významně. Další šířka pásma byla spotřebována něčím a protokoly přístupu poukázaly na provoz crawleru jako primární řidič. To se zdálo rozumné pro web takové velikosti, takže obavy byly odloženy jako náklad na podnikání.
Druhá stopa byla zatížení serveru. Využití CPU během hodin špičkového provozu bylo konzistentně vyšší, než se očekávalo. Aplikace byla dobře optimalizovaná, s ukládáním do mezipaměti na více vrstvách a specifikace hardwaru by měla bez problémů zvládnout provoz. Ale průměry zatížení vyprávěly jiný příběh. Server pracoval tvrdě a přidaná práce byla korelaci ne s špičkami provozu orientovanými na uživatele, ale s udržovaným, non-stop objemem požadavků, který nikdy neklesl na nulu. Skutečný lidský provoz se řídí předvídatelnými vzory. Dosahuje vrcholu během pracovní doby, klesá v noci a liší se podle dne v týdnu. Provoz botů běží třiadvacet hodin denně, sedm dní v týdnu, konstantní sazba a bylo vidět v grafech zatížení jako základní linie, která nikdy neklesl pod určitou prahovou hodnotu.
Třetí stopa, a ta, která nakonec spustila vyšetřování, byla analytická nesrovnalost. Analýza Google Analytics, která sleduje pouze návštěvníky spouštějící JavaScript, ukazovala podstatně méně provozu než protokoly přístupu serveru. Rozdíl mezi těmito dvěma čísly byl provoz botů. Skutečné prohlížeče spouštějí JavaScript a zaregistrují se v analýtice. Boti, kteří si vyžádají stránky HTML bez spuštění JavaScriptu, se zobrazí v protokolech serveru, ale ne v analýtice. Významná mezera mezi těmito dvěma je silným indikátorem těžké aktivity botů a mezera na tomto webu byla obrovská.
Vyzbrojeni těmito pozorováními vyšetřování začalo vážně. Vzorek tisíc položek protokolu přístupu tvrdících, že jsou od Googlebota, byl extrahován a jejich IP adresy zkontrolovány vůči publikovaným rozsahům IP Googlu. Výsledek byl devastující. Přes sedm set z těchto tisíce požadavků pocházelo z IP adres, které neměly žádné spojení s Googlem. Pocházely z AWS, Hetzner, OVH a různých dalších poskytovatelů hostingu. Řetězec uživatelského agenta řekl Googlebot, ale IP adresa řekla náhodný server v datovém centru. Rozšíření analýzy na Bingbot, crawler ChatGPT a dalších tvrdených identit vyprodukovalo podobné výsledky. Provoz byl přemírou falešný.
Jak jedno volání API ověří identitu jakéhokoli crawleru
Proces ověřování, který odhalil falešný provoz, je koncepčně jednoduchý, ale prakticky únavný na implementaci od nuly. Každý hlavní vyhledávač a crawler funguje ze specifické sady rozsahů IP vázaných na autonomní číslo systému jejich společnosti. Google používá AS15169. Microsoft používá několik ASN pro infrastrukturu Bingu. Crawler OpenAI používá vlastní určené rozsahy. Ověření crawleru znamená vzití IP adresy příchozího požadavku, provedení zpětného vyhledávání DNS, potvrzení, že doména odpovídá očekávanému vzoru, provedení dopředného vyhledávání DNS pro potvrzení, že IP odpovídá doméně, a kontrolu, zda IP spadá do očekávaného ASN. Toto víceúrovňové ověření zachycuje sofistikované podvrhy, které mohou projít jednu nebo dvě kontroly, ale selhávají v úplném řetězci.
API detekce botů zapouzdřuje celý řetězec ověření do jednoho volání. Pošlete IP adresu a tvrdený řetězec uživatelského agenta a API vrátí rozsudek: legitimní nebo falešný, spolu s důkazy podporujícími určení. ASN IP adresy, výsledek zpětného DNS, očekávaný ASN pro tvrdoženou identitu a úroveň důvěry posouzení. Pro sedmdesát procent provozu, který byl falešný, důkazy byly jasné. IP adresy patřily poskytovatelům cloudového hostingu, zpětné DNS vrátily obecné názvy hostitelů, které neměly nic společného s Google nebo Microsoft, a ASN byl zcela nesprávný pro tvrdoženou identitu.
Co činí tento přístup definitivní spíše než heuristickou, je, že se spoléhá na ověřitelné údaje o infrastruktuře sítě, nikoli na analýzu chování. Sofistikovaný bot může napodobovat vzory procházení lidí, randomizovat načasování požadavků, spouštět JavaScript a dokonce řešit CAPTCHA. Ale nemůže změnit autonomní číslo systému IP adresy, ze které se připojuje. Pokud požadavek tvrdí, že je Googlebot, ale pochází z datového centra AWS, je falešný. Neexistuje žádná šedá zóna, žádný skóre pravděpodobnosti, žádná obava z falešně pozitivního. Infrastruktura sítě nepolyká a API jednoduše zpřístupňuje tuto pravdu ve formátu, kterou lze konzumovat programově.
Co se změnilo po identifikaci falešného provozu
Vědět, že sedmdesát procent provozu bylo falešné, okamžitě změnilo každé obchodní rozhodnutí, které bylo založeno na metrikách provozu. Skutečné publikum bylo tři miliony měsíčních návštěvníků, ne deset milionů. Skutečná míra konverze byla více než třikrát vyšší než vypočítaná míra, protože jmenovatel byl nafouknutý sedmi miliony neexistujících uživatelů. Skutečné metriky zapojení byly respektabilní spíše než ostudné nízké. Každá zpráva, která byla vytvořena, každá schůze strategie, která odkazovala na čísla provozu, každé rozhodnutí o plánování kapacity, které bylo založeno na projekcích růstu, bylo postaveno na základě znečištěného údaje. Falešný provoz nejen spotřebovával prostředky serveru. Zkreslilo celý analytický rámec podnikání.
Okamžitou technickou akcí byla implementace blokování na úrovni serveru. Každý příchozí požadavek, který tvrdil, že je vyhledávací vyhledávač, byl ověřen vůči API v reálném čase. Požadavky, které selhaly ověření, byly blokovány dříve, než dosáhly aplikační vrstvy. Efekt byl dramatický a okamžitý. Spotřeba šířky pásma klesla ostře. Využití CPU serveru během mimohodin kleslo na zlomek své předchozí úrovně. Doba odezvy aplikace se zlepšila, protože server již neztrácely prostředky na vykreslování stránky pro boty, které by nikdy neindexovali. Náklad na hosting se snížil proporcionálně.
Analytické čištění trvalo déle, ale bylo stejně důležité. S falešným provozem filtrovaným se analytika stala důvěryhodnou poprvé. Vzory chování uživatele se staly viditelnými bez hlučité vrstvy aktivity botů. Lze identifikovat skutečné trendy provozu a korelovat s marketingovými úsilími. Obsah, který byl skutečně přitahován návštěvníky člověka, lze rozlišit od obsahu, který přitahoval pouze boty. Tato jasnost transformovala rozhodování z hádání založeného na znečištěném údaji na analýzu založenou na realitě.
Měřítko problému na internetu
Tato zkušenost nebyla odlehlou. Průmyslové odhady důsledně umisťují provoz botů na třicet až padesát procent všeho internetového provozu celosvětově a pro jednotlivé weby se podíl může být mnohem vyšší. Weby s velkým počtem stránky, vysokou autoritou domény nebo cenným obsahem přitahují provoz botů neúměrně. Škrápače, falešné crawlery, boty konkurenční inteligence, boty monitorování cen, boty analýzy SEO a různé příchutě škodlivé automatizace přispívají k celkovému. Většina obsluhy webu nemá viditelnost do tohoto provozu, protože se spoléhají na analytické nástroje, které měří pouze návštěvníky spouštějící JavaScript, což ponechávají celou vrstvu botů neviditelnou.
Finanční dopad se vztahuje kromě nákladů na šířku pásma. Reklamní platformy účtují na základě impresí a kliknutí. Pokud provoz botů generuje ad imprese, tyto imprese nafukují čísla a zkreslují metriky výkonu kampaně. Rámce testování A/B, které zahrnují návštěvy botů v jejich vzorku, produkují nespolehlivé výsledky. Omezení sazby a systémy detekce zneužití kalibrované vůči celkovému provozu budou nesprávně vyladěny, pokud je valná část tohoto provozu ne člověk. Dokonce i strategie SEO může být postižena, protože protokoly serveru ukazující těžkou aktivitu crawlu mohou být omylem přijati za důkaz, že vyhledávače hluboce indexují web, když ve skutečnosti crawlery jsou falešné a skutečné vyhledávače přidělují mnohem menší rozpočet crawlování.
Služba detekce botů se zrodila přímo z této zkušenosti. Logika ověřování, která byla vytvořena k čištění provozu jednoho webu, byla zobecněna na API, které může jakýkoli web použít k ověření identit crawleru. Osm specifických detektorů pokrývajících Google, Bing, OpenAI, Yandex, DuckDuckGo, Qwant a Seznam poskytují cílené ověření pro nejčastěji vydávané crawlery. Výsledkem je, že jakýkoli operátor webu může spustit stejné vyšetřování, které odhalilo obrázek sedmdesáti procent falešného provozu, a většina z nich obnoví, že jejich vlastní čísla jsou podobně nafouknutá. Prvním krokem k řešení problému je prokázat, že existuje, a tento důkaz je jednoho volání API.
Často kladené otázky
Jak mohu říci, že můj web má významný falešný provoz botů?
Porovnejte své protokoly přístupu serveru vůči analýze na bázi JavaScriptu. Velký rozdíl mezi těmito dvěma čísly znamená podstatnou aktivitu botů. Kromě toho zkontrolujte IP adresy požadavků tvrdících, že jsou od vyhledávačů. Pokud mnozí pocházejí od poskytovatelů cloudového hostingu spíše než očekávaných sítí společnosti, jsou falešné.
Jaký je rozdíl mezi skutečným Googleboten a falešným?
Skutečný Googlebot pochází výhradně z IP adres v rámci autonomního systému společnosti Google AS15169. Falešný Googlebot používá stejný řetězec uživatelského agenta, ale připojuje se z IP adres patřících poskytovatelům cloudového hostingu, jako je AWS, DigitalOcean nebo Hetzner. Řetězec uživatelského agenta je triviálně snadné podvrhnout, ale IP adresa odhaluje skutečné počátky.
Bude blokování falešných botů ovlivňovat můj ranking vyhledávačů?
Ne. Blokování falešných botů pouze ovlivní požadavky z IP adres, které nepatří legitimitnímu vyhledávači. Skutečný Googlebot, Bingbot a další legitimní crawlery budou normálně přistupovat na web, protože prošli kontrolou ověření. Jsou blokovány pouze vetřelci.
Kolik šířky pásma lze ušetřit blokováním falešného provozu botů?
Úspory závisí na proporci falešného provozu. Weby s těžkou aktivitou falešných botů často vidí redukci šířky pásma čtyřicet až šedesát procent po implementaci ověření a blokování. Pro weby s vysokými náklady na šířku pásma se to může přeložit na významné měsíční úspory.
Mohou falešní boti spouštět JavaScript a objevit se v Analýze Google?
Některé sofistikované boti skutečně spouštějí JavaScript, což znamená, že se mohou objevit v analytických nástrojích. Však valná většina falešných crawlerů je jednoduché generátory žádostí HTTP, které nevykreslují JavaScript. Ověření na bázi IP zachycuje oba typy, protože se nespoléhá na analýzu chování, ale na ověřitelný síťový původ požadavku.
Jak API detekce botů zpracovává nové nebo neznámé crawlery?
API obsahuje specifické detektory pro osm nejčastěji vydávaných crawlerů. U neznámých uživatelských agentů API poskytuje informace ASN a data zpětného DNS, která umožňují volajícímu provést vlastní určení. Obecný princip se vztahuje univerzálně: ověřte IP adresu vůči známé infrastruktuře tvrdožené identity.