Bulgarian Does Not Exist for Most Subtitle Tools So I Built One That Supports 98 Languages
The dropdown menu is the first thing you see when uploading a video to any subtitle tool. A long list of languages, alphabetically sorted, sometimes with flags next to them. English is always there, usually at the top. Spanish, French, German, Portuguese. All present and accounted for. Scroll further and you might find Chinese, Japanese, Korean. Keep scrolling. Arabic. Hindi, sometimes. And then the list ends, or the language you actually need is simply not there. Bulgarian. Not listed. Not as an option, not as a beta feature, not even as an unsupported entry with a warning label. It just does not exist in the product's universe.
This is not a minor inconvenience. When the language is missing entirely, the tool is not partially useful. It is completely useless. There is no workaround that produces acceptable results. The audio goes in, and either the tool rejects it outright or it tries to process it as something else. The output is garbage, every single time.
The experience of being a content creator whose primary language falls outside the narrow band of "commercially interesting" languages is one of constant adaptation. It means learning to work around tools rather than with them. It means accepting that most software was simply not built with you in mind, and that the features marketed as "global" or "multilingual" really mean "we support the ten languages that make us the most money."
The Russian Workaround and Why It Fails
When Bulgarian is not on the list, Russian becomes the default workaround. The two languages share the Cyrillic alphabet, and certain words have similar roots. On paper, it seems like a reasonable approximation. In practice, it is a disaster that creates more work than doing everything by hand from scratch.
Russian transcription applied to Bulgarian audio produces something that looks almost right at first glance. The Cyrillic characters appear on screen, the words have a vaguely Slavic shape to them, and maybe one in three is actually correct. But "almost right" in subtitles means completely wrong. A viewer reading subtitles that are 60% accurate does not get 60% of the message. They get confusion, distraction, and the impression that the creator did not care enough to proofread their own content.
The editing process that follows is where the real time gets lost. A five-minute video might produce 180 to 220 individual subtitle segments. When the transcription language is wrong, every single one of those segments needs to be opened, read, compared against the actual audio, and manually retyped. Not corrected, but retyped entirely, because the Russian transcription often bears so little resemblance to the Bulgarian original that it is faster to delete the text and start fresh than to try fixing it character by character. Two hours of manual editing for a five-minute video is not unusual. For someone running multiple YouTube channels with regular upload schedules, that arithmetic simply does not hold up.
This exact problem extends far beyond Bulgarian. Hindi creators face it when their regional dialect gets flattened into a generic Hindi transcription that misses half the vocabulary. Thai creators deal with tonal interpretation errors that turn every other sentence into nonsense. Vietnamese, Serbian, Tagalog, Swahili. The list of languages that get either ignored or poorly approximated by mainstream subtitle tools is long, and the creators who speak those languages have been quietly absorbing the extra workload for years.
Why the Language Gap Exists in the First Place
Subtitle tools are businesses, and businesses allocate development resources where the revenue is. English-speaking markets represent the largest share of paying customers for nearly every SaaS product in the video creation space. Spanish and Portuguese cover most of Latin America. French adds parts of Europe and Africa. German, Japanese, Korean. Each one opens a market with significant purchasing power. A product that supports these ten or twelve languages can claim to serve the majority of its potential customer base, and from a purely financial perspective, that claim is defensible.
Adding a new language to a transcription system is not trivial. It requires training data, quality testing, ongoing maintenance, and support documentation. For a language spoken by seven million people, like Bulgarian, the cost-to-revenue calculation rarely justifies the investment when the same engineering hours could go toward improving English transcription accuracy from 95% to 97%, which affects millions of paying users.
The result is a market where the top fifteen or twenty languages receive excellent support, the next thirty get passable coverage, and everything else is either missing or so poorly implemented that it should not be listed as a feature at all. This is not malicious. It is the predictable outcome of building products that optimize for the largest possible audience rather than the broadest possible coverage. But understanding why it happens does not make it any less frustrating when you are the one staring at a dropdown menu that does not include your language.
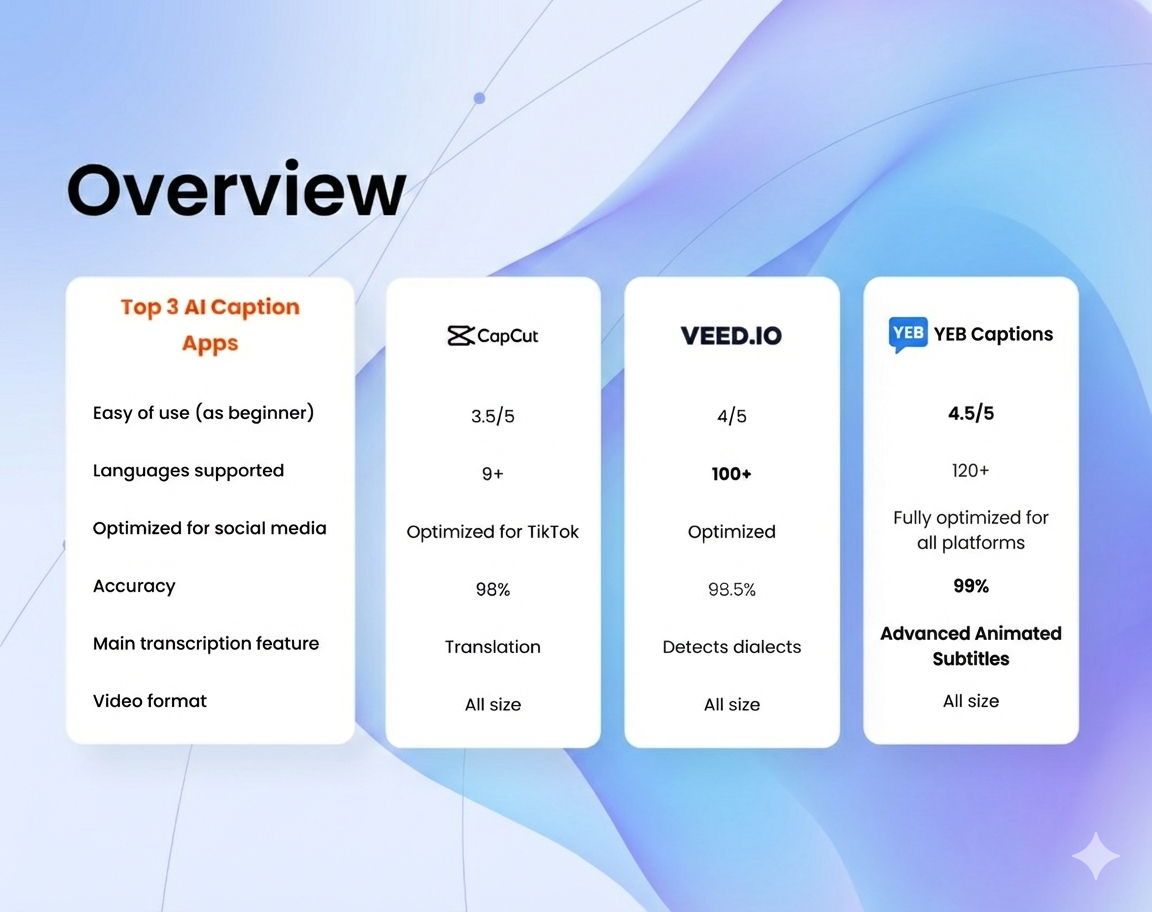
The subtitle generator on YEB was built with a different set of priorities. Instead of starting with the most commercially valuable languages and working outward, the transcription engine was selected specifically for its breadth of language support. Ninety-eight languages from the start, not as a roadmap aspiration, but as a launch requirement. Bulgarian, Serbian, Hindi, Thai, Vietnamese, Tagalog, and dozens of others that rarely appear in competitor feature lists are all handled natively, with the same transcription pipeline and the same quality standards as English or Spanish.
What Proper Language Support Actually Means in Practice
Supporting a language does not just mean accepting audio in that language and returning some text. It means the transcription engine understands the phonetic structure, the common vocabulary, the cadence and rhythm of natural speech in that language. It means that when a Bulgarian speaker records a video, the output does not need to be manually corrected beyond the occasional proper noun or technical term that any transcription system might stumble on.
On YEB Captions, uploading a Bulgarian-language video works exactly the same as uploading an English one. The language is selected from the full list of 98 options, the audio is processed, and the transcription comes back as properly timed subtitle segments in Bulgarian. No Russian approximation, no manual retyping, no two-hour editing sessions for a five-minute video. The segments can still be edited individually if needed, such as a misheard word here or a name that needs correction there, but the baseline accuracy makes those edits measured in minutes rather than hours.
The same applies to subtitle translation. Content originally transcribed in Bulgarian can be translated into any of the other supported languages before rendering. A music video with Bulgarian lyrics can be published with English, Spanish, or Japanese subtitles without going through a separate translation workflow. For creators who publish content aimed at international audiences, this eliminates an entire layer of manual work that previously required either hiring a translator or spending an evening with a dictionary and a lot of patience.
The point is not that YEB Captions is the only tool in the world that supports Bulgarian. A handful of tools offer it in some form. The point is that proper support, where the transcription quality is genuinely usable without extensive manual correction, remains rare for languages outside the mainstream, and the gap between "listed as supported" and "actually works well" is often enormous.
The Broader Problem of Building Tools for Everyone
There is an assumption baked into most software development that "everyone" means "everyone who speaks a major language." The feature pages say "global" and "multilingual" while the actual language list tells a much narrower story. This is not limited to subtitle tools. Machine translation services, voice assistants, OCR systems, and search engines all exhibit the same pattern of deep support for a small number of languages and shallow or nonexistent support for the rest.
What makes subtitle tools particularly noticeable is the nature of the failure. When a voice assistant misunderstands a command, the user can repeat it or type instead. When a subtitle tool produces garbage text, that text ends up burned into a video that gets published to hundreds or thousands of viewers. The error is permanent, public, and directly tied to the creator's professional reputation. Getting it wrong is not just an inconvenience; it is a visible quality failure that viewers notice immediately.
Creators who speak underserved languages have developed all sorts of workarounds over the years. Some record their videos in English even when their audience speaks something else. Some skip subtitles entirely and accept the lower engagement numbers. Some use the closest available language and then spend hours fixing the output, absorbing a labor cost that their English-speaking competitors simply do not have to deal with. None of these are real solutions. They are compromises forced by a market that decided certain languages were not worth supporting properly.
Building captions.yeb.to with 98 languages was partly a response to this specific frustration and partly a recognition that the underserved segment of the market is much larger than most companies seem to think. Seven million Bulgarian speakers is a small number compared to English or Mandarin. But add up all the languages that fall into the "not commercially interesting" category, including the Serbians, the Thais, the Vietnamese, the Tagalog speakers, the Swahili speakers, and you are talking about hundreds of millions of people who have been poorly served by subtitle tools for years. That is not a niche. That is a market that simply has not been addressed, and the landscape of caption apps is slowly starting to reflect that reality.
Frequently Asked Questions
Which subtitle generators support Bulgarian language
Very few subtitle tools include Bulgarian as a supported language, and even fewer produce usable transcription quality. YEB Captions supports Bulgarian as one of 98 languages with native transcription, meaning the output does not require the Russian-language workaround that most other tools force Bulgarian speakers to use.
Can an AI subtitle generator handle non-Latin scripts accurately
Accuracy depends entirely on the transcription engine and how much training data it has for the specific language. Cyrillic, Devanagari, Thai, and Arabic scripts are all supported by modern transcription models, but many subtitle tools only include a handful of these. Tools built with broad multilingual support from the start tend to handle non-Latin scripts significantly better than those that added them as afterthoughts.
Why do most subtitle tools only support 10 to 15 languages
Language support requires training data, testing, and ongoing maintenance. Most companies focus their resources on the languages that generate the most revenue, which means English, Spanish, French, German, and a few others. Languages spoken by smaller populations rarely justify the investment from a pure business perspective, which is why they get left out of most products entirely.
Is auto subtitle generation accurate enough to skip manual editing
For well-supported languages like English and Spanish, modern transcription accuracy is typically above 90%, which means only minor corrections are needed. For less common languages, accuracy varies dramatically between tools. The key difference is whether the tool was designed to support the language from the start or added it as an afterthought with minimal testing.
How do I add subtitles to a video in a language that most tools do not support
The most common workaround is selecting a related language and manually correcting the output, which is extremely time-consuming. The better option is using a tool that actually supports the language natively. YEB's subtitle generator covers 98 languages and produces transcriptions that require minimal correction even for languages like Bulgarian, Serbian, and Thai that most competitors ignore.
What is the difference between subtitle translation and subtitle generation
Subtitle generation means converting spoken audio into text in the same language. Subtitle translation means taking existing subtitles and converting them into a different language. YEB Captions supports both. A video can be transcribed in its original language and then translated into any of the other supported languages before rendering.